
What is a Knowledge Graph?
A knowledge graph is a structured representation of knowledge that describes entities and the relationships between them.
Knowledge graphs are a part of “knowledge representation“, a field of Artificial Intelligence (AI) that deals with presenting data in a way that enables machines to engage in reasoning, problem-solving, decision-making, and inferencing.
The versatility of knowledge graphs extends across various domains, with use cases that include:
Knowledge graphs empower machines to extract meaningful knowledge from data by presenting information in a machine-readable format.
But did you know you can also create a “content” knowledge graph that is particularly useful for SEO initiatives? Although structured like a general knowledge graph, a content knowledge graph functions as a representation of the content on your website.
This graph can be published externally for search engines to consume, be employed for internal AI projects, or be used to identify content gaps.
Moreover, these graphs establish a robust foundation for developing more extensive marketing knowledge graphs if you have additional data sources you’d like to bring into the fold.
But before we get into that, this article will explore the basic components of a knowledge graph to enable you to develop your own content knowledge graph using the content on your website.
Anatomy of a Content Knowledge Graph
At its simplest form, a knowledge graph fundamentally consists of nodes and edges.
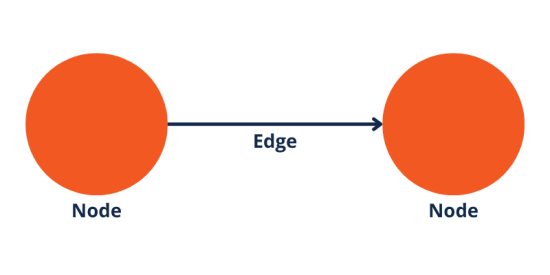
Nodes represent entities within a knowledge graph, and edges interconnect these nodes, delineating the relationships between them.
To fully understand how a knowledge graph works, it’s important to know the technologies required to build them.
Our focus in this section is to guide you through the key terminology and functions that are critical to the development of a robust content knowledge graph.
Uniform Resource Identifier (URI)
In the realm of knowledge graphs, the Uniform Resource Identifier (URI) plays a crucial role in uniquely identifying entities. A URI is a distinctive string of characters designed to distinguish and disambiguate a specific resource on the web.
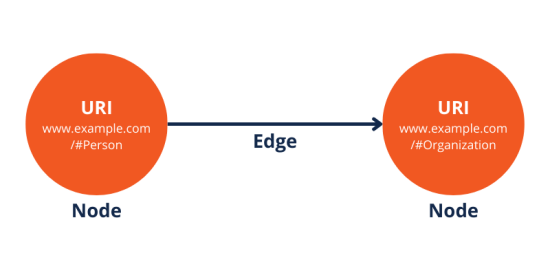
Similar to license plates on cars that enable individual identification despite many people sharing the same make and model, URIs serve a similar function by ensuring the unique identification of various resources amidst the vast expanse of the internet.
At Schema App, we generate HTTPS URIs for entities defined in your Schema Markup, as shown in the image below. These URIs appear in the @id attribute. They allow you to link the entities on your site within your markup and enable search engines to identify the entities in your knowledge graph.

This systematic identification enables efficient communication and access to resources across different platforms and technologies. Within the context of a knowledge graph, URIs represent entities.
Entities
An entity, as defined by Google, denotes a single, unique, well-defined, and distinguishable thing or idea. It possesses defining characteristics or attributes such as size, color, and duration. However, an entity’s true significance emerges when it is described in relation to other entities, giving it contextual meaning.
This is where RDF Triples play a pivotal role, providing the framework to represent these interconnected relationships between entities within a knowledge graph. But first, what is RDF?
RDF
RDF, which stands for Resource Description Framework, is a standardized method for expressing data in the form of a directed graph using subject-predicate-object statements, commonly referred to as “triples.”
RDF Triples
The foundational unit of a knowledge graph is the triple. It comprises two nodes that represent entities connected by a single edge to articulate their relationship. Represented as “subject-predicate-object” statements, a triple illustrates how an entity (subject) links to another entity or a simple value (object) through a specific property (predicate).
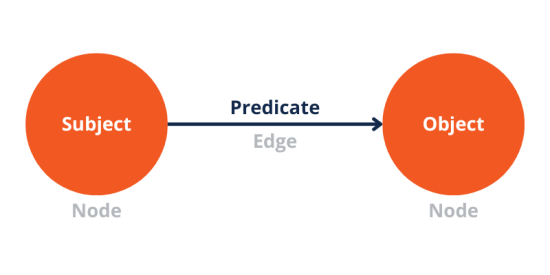
As these triples combine, they form interconnected graphs of resources, laying the groundwork for a comprehensive knowledge graph. However, to provide meaning to the machine, you must express these triples in a machine-readable format.
You can express RDF triples in a variety of formats, including:
- Turtle
- RDF/XML
- And JSON-LD
The most widely adopted format is JSON-LD, which we utilize here at Schema App.
JSON-LD
JSON-LD, or JSON for Linked Data, is a serialization format for expressing RDF triples. It is relatively easy for humans to read and write and also for machines to consume. It is also the preferred Schema Markup format for search engines like Google.
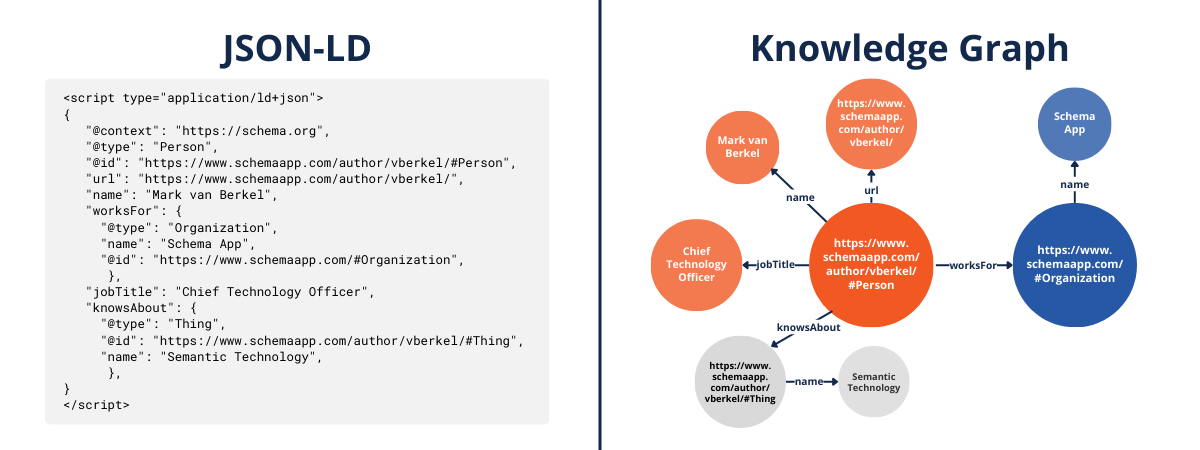
JSON-LD code allows machines to understand RDF statements about entities.
For example, Mark van Berkel is an author for the Schema App blog, and his author page states that he works for the organization Schema App. On the left is the Schema Markup expressed in JSON-LD telling machines that Mark van Berkel (Person) works for Schema App (Organization). On the right is this same code visualized as an RDF triple, depicting these same entities and illustrating the relationships between them.

Ontologies
The last component in a knowledge graph is an ontology.
In Information Science, an ontology is a “formal, explicit specification of a shared conceptualization,” essentially serving as a blueprint for defining what exists in a data model (i.e. the method for describing contents within a database).
This model typically encompasses three key elements.
First, we have classes, also known as types, representing categories of entities such as an organization, event, or person.
Secondly, attributes, aka properties, are used to describe an entity. For instance, a Person entity might possess a name as one of its attributes.
Lastly, relationships, which are also represented by properties, delineate how one entity connects to another. These are similar to attributes in that they describe an entity, but more specifically, they describe how one entity connects to another entity.
For example, a Person may have a parent, child, or colleague relationship with another Person who will have their own attributes.
A wide variety of ontologies, vocabularies, and glossaries exist for categorizing and relating data, with Schema.org standing out as one of the most widely used in SEO. While technically a vocabulary and not a strict ontology, Schema.org effectively fulfills the role of describing categories of things and the relationships between them.
Building a Content Knowledge Graph with Schema.org
Founded in 2011 by Google, Bing, Yahoo, and Yandex, Schema.org emerged as a collaborative effort to enhance the web by introducing a standardized vocabulary. This initiative aimed to transform human language into a structured, machine-readable language.
All major search engines would support this language, improving their ability to match search queries with relevant results, making it beneficial for SEO purposes.
While SEO strategies commonly employ Schema.org, its utility extends beyond; it can also serve as a robust tool for constructing a knowledge graph.
Leveraging the Schema.org vocabulary allows you to organize your website content into a graph of interconnected entities. To achieve this, you can utilize the types and properties defined by Schema.org to express RDF triples in a machine-readable format like JSON-LD, all while representing your entities with URIs.
See how all of these terms come together?
This amalgamation of elements effectively creates a content knowledge graph for your organization.
Construct a Content Knowledge Graph for Your Organization
Developing your own content knowledge graph is essential for optimizing your semantic SEO strategy. It readies your content for the future of search and drives higher-quality traffic to your site.
Knowledge graphs empower search engines to infer knowledge through additional contextual information, bridging gaps for more relevant results. As such, this deeper comprehension should drive more qualified traffic to your site and boost the CTR for relevant pages.
At Schema App, we specialize in building and managing content knowledge graphs through the use of Schema Markup. Our dynamic authoring solutions ensure your Schema Markup is always descriptive, interconnected, and up-to-****.
Whether you’re integrating Schema Markup into your SEO strategy or aspiring to transform your content into a reusable data layer, Schema App has you covered.
Interested in building a content knowledge graph for your own organization but aren’t sure where to start? Schema App handles the technical aspects, enabling you to reap the benefits of having a well-constructed content knowledge graph without imposing the technical burden on your internal teams.
Contact our team today to get started.

Jasmine is the Product Manager at Schema App. Schema App is an end-to-end Schema Markup solution that helps enterprise SEO teams create, deploy and manage Schema Markup to stand out in search.



