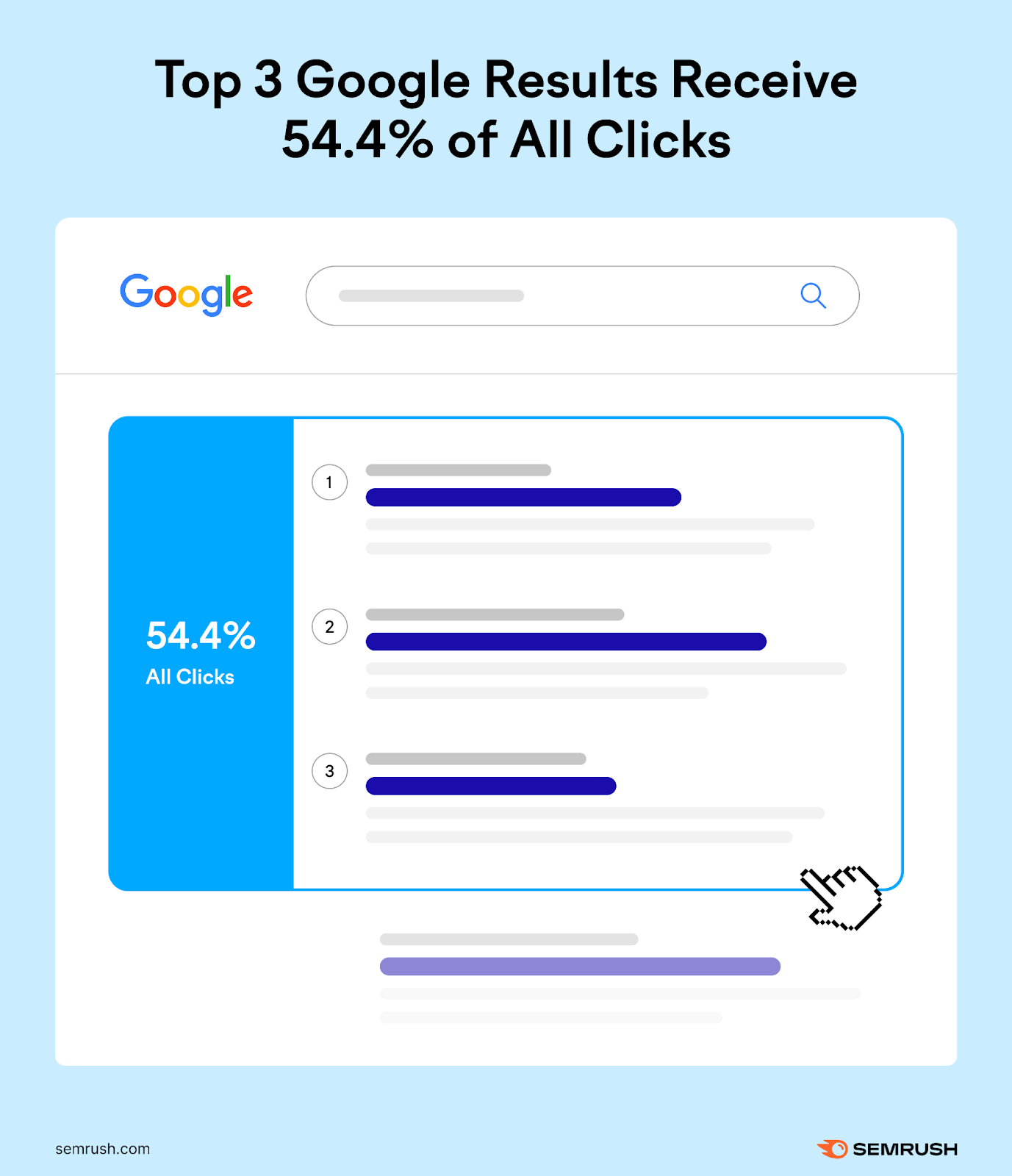
The new oil isn’t data or attention. It’s words. The differentiator to build next-gen AI ****** is access to content when normalizing for computing power, storage, and energy.
But the web is already getting too small to satiate the hunger for new ******.
Some executives and researchers say the industry’s need for high-quality text data could outstrip supply within two years, potentially slowing AI’s development.
Even fine-tuning doesn’t seem to work as well as simply building more powerful ******. A Microsoft research case study shows that effective prompts can outperform a fine-tuned model by 27%.
We were wondering if the future will consist of many small, fine-tuned, or a few big, all-encompassing ******. It seems to be the latter.
There is no AI strategy without a data strategy.
Hungry for more high-quality content to develop the next generation of large language ****** (LLMs), model developers start to pay for natural content and revive their efforts to label synthetic data.
For content creators of any kind, this new flow of money could carve the path to a new content monetization model that incentivizes quality and makes the web better.
Boost your skills with Growth Memo’s weekly expert insights. Subscribe for free!
KYC: AI
If content is the new oil, social networks are oil rigs. Google invested $60 million a year in using Reddit content to train its ****** and surface Reddit answers at the top of search. Pennies, if you ask me.
YouTube CEO Neal Mohan recently sent a clear message to OpenAI and other model developers that training on YouTube is a no-go, defending the company’s massive oil reserves.
The New York Times, which is currently running a lawsuit against OpenAI, published an article stating that OpenAI developed Whisper to train ****** on YouTube transcripts, and Google uses content from all of its platforms, like Google Docs and Maps reviews, to train its AI ******.
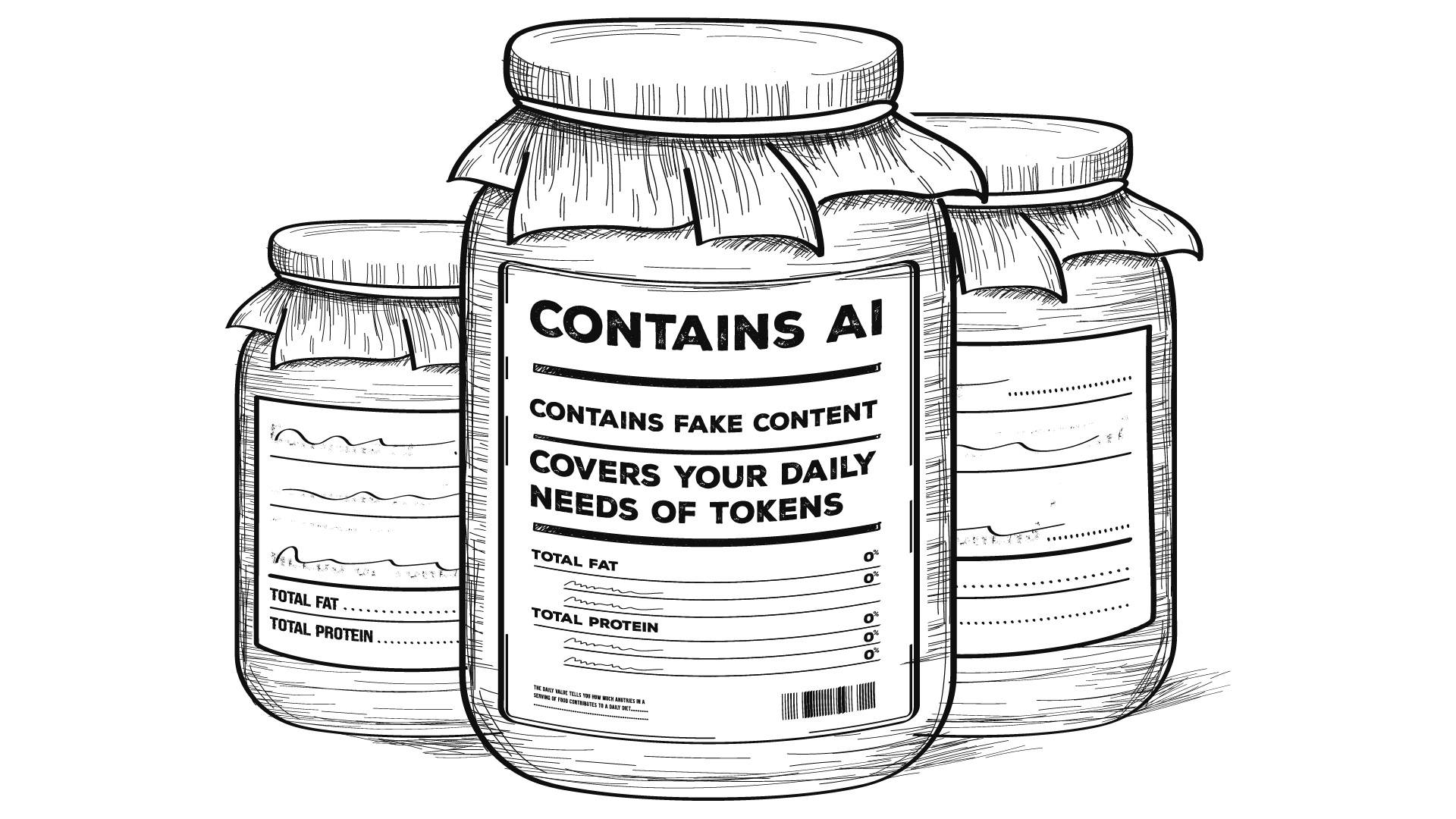
Generative AI data providers like Appen or Scale AI are recruiting (human) writers to create content for LLM model training.
Make no mistake, writers aren’t getting rich writing for AI.
For $25 to $50 per hour, writers perform tasks like ranking AI responses, writing short stories, and fact-checking.
Applicants must have a Ph.D. or master’s degree or are currently attending college. Data providers are clearly looking for experts and “good” writers. But the early signs are promising: Writing for AI could be monetizable.
 Image Credit: Kevin Indig
Image Credit: Kevin Indig Image Credit: Kevin Indig
Image Credit: Kevin IndigModel developers look for good content in every corner of the web, and some are happy to sell it.
Content platforms like Photobucket sell photos for five cents to one dollar a piece. Short-form videos can get $2 to $4; longer films cost $100 to $300 per hour of footage.
With billions of photos, the company struck oil in its backyard. Which CEO can withstand such a temptation, especially as content monetization is getting harder and harder?
From Free Content:
Publishers are getting squeezed from multiple sides:
- Few are prepared for the death of third-party cookies.
- Social networks send less traffic (Meta) or deteriorate in quality (X).
- Most young people get news from TikTok.
- SGE looms on the horizon.
Ironically, labeling AI content better might help LLM development because it’s easier to separate natural from synthetic content.
In that sense, it’s in the interest of LLM developers to label AI content so they can exclude it from training or use it the right way.
Labeling
Drilling for words to train LLMs is just one side of developing next-gen AI ******. The other one is labeling. Model developers need labeling to avoid model collapse, and society needs it as a shield against fake news.
A new movement of AI labeling is rising despite OpenAI dropping watermarking due to low accuracy (26%). Instead of labeling content themselves, which seems futile, big tech (Google, YouTube, Meta, and TikTok) pushes users to label AI content with a carrot/stick approach.
Google uses a double-pronged approach to fight AI spam in search: prominently showing forums like Reddit, where content is most likely created by humans, and penalties.
From AIfficiency:
Google is surfacing more content from forums in the SERPs is to counter-balance AI content. Verification is the ultimate AI watermarking. Even though Reddit can’t prevent humans from using AI to create posts or comments, chances are lower because of two things Google search doesn’t have: Moderation and Karma.
Yes, Content Goblins have already taken aim at Reddit, but most of the 73 million daily active users provide useful answers.1 Content moderators punish spam with bans or even kicks. But the most powerful driver of quality on Reddit is Karma, “a user’s reputation score that reflects their community contributions.” Through simple up or downvotes, users can gain authority and trustworthiness, two integral ingredients in Google’s quality systems.
Google recently clarified that it expects merchants not to remove AI metadata from images using the IPTC metadata protocol.
When an image has a tag like compositeSynthetic, Google might label it as “AI-generated” anywhere, not just in shopping. The punishment for removing AI metadata is unclear, but I imagine it like a link penalty.
IPTC is the same format Meta uses for Instagram, Facebook, and WhatsApp. Both companies give IPTC metatags to any content coming out from their own LLMs. The more AI tool makers follow the same guidelines to mark and tag AI content, the more reliable detection systems work.
When photorealistic images are created using our Meta AI feature, we do several things to make sure people know AI is involved, including putting visible markers that you can see on the images, and both invisible watermarks and metadata embedded within image files. Using both invisible watermarking and metadata in this way improves both the robustness of these invisible markers and helps other platforms identify them.
The downsides of AI content are small when the content looks like AI. But when AI content looks real, we need labels.
While advertisers try to get away from the AI look, content platforms prefer it because it’s easy to recognize.
For commercial artists and advertisers, generative AI has the power to massively speed up the creative process and deliver personalized ads to customers on a large scale – something of a holy grail in the marketing world. But there’s a catch: Many images AI ****** generate feature cartoonish smoothness, telltale flaws, or both.
Consumers are already turning against “the AI look,” so much so that an uncanny and cinematic Super Bowl ad for Christian charity He Gets Us was accused of being born from AI –even though a photographer created its images.
YouTube started enforcing new guidelines for video creators that say realistic-looking AI content needs to be labeled.
Challenges posed by generative AI have been an ongoing area of focus for YouTube, but we know AI introduces new risks that bad actors may try to exploit during an election. AI can be used to generate content that has the potential to mislead viewers – particularly if they’re unaware that the video has been altered or is synthetically created. To better address this concern and inform viewers when the content they’re watching is altered or synthetic, we’ll start to introduce the following updates:
- Creator Disclosure: Creators will be required to disclose when they’ve created altered or synthetic content that’s realistic, including using AI tools. This will include election content.
- Labeling: We’ll label realistic altered or synthetic election content that doesn’t violate our policies, to clearly indicate for viewers that some of the content was altered or synthetic. For elections, this label will be displayed in both the video player and the video description, and will surface regardless of the creator, political viewpoints, or language.
The biggest imminent fear is fake AI content that could influence the 2024 U.S. presidential election.
No platform wants to be the Facebook of 2016, which saw lasting reputational damage that impacted its stock price.
Chinese and Russian state actors have already experimented with fake AI news and tried to meddle with the Taiwanese and coming U.S. elections.
Now that OpenAI is close to releasing Sora, which creates hyperrealistic videos from prompts, it’s not a far jump to imagine how AI videos can cause problems without strict labeling. The situation is tough to get under control. Google Books already features books that were clearly written with or by ChatGPT.
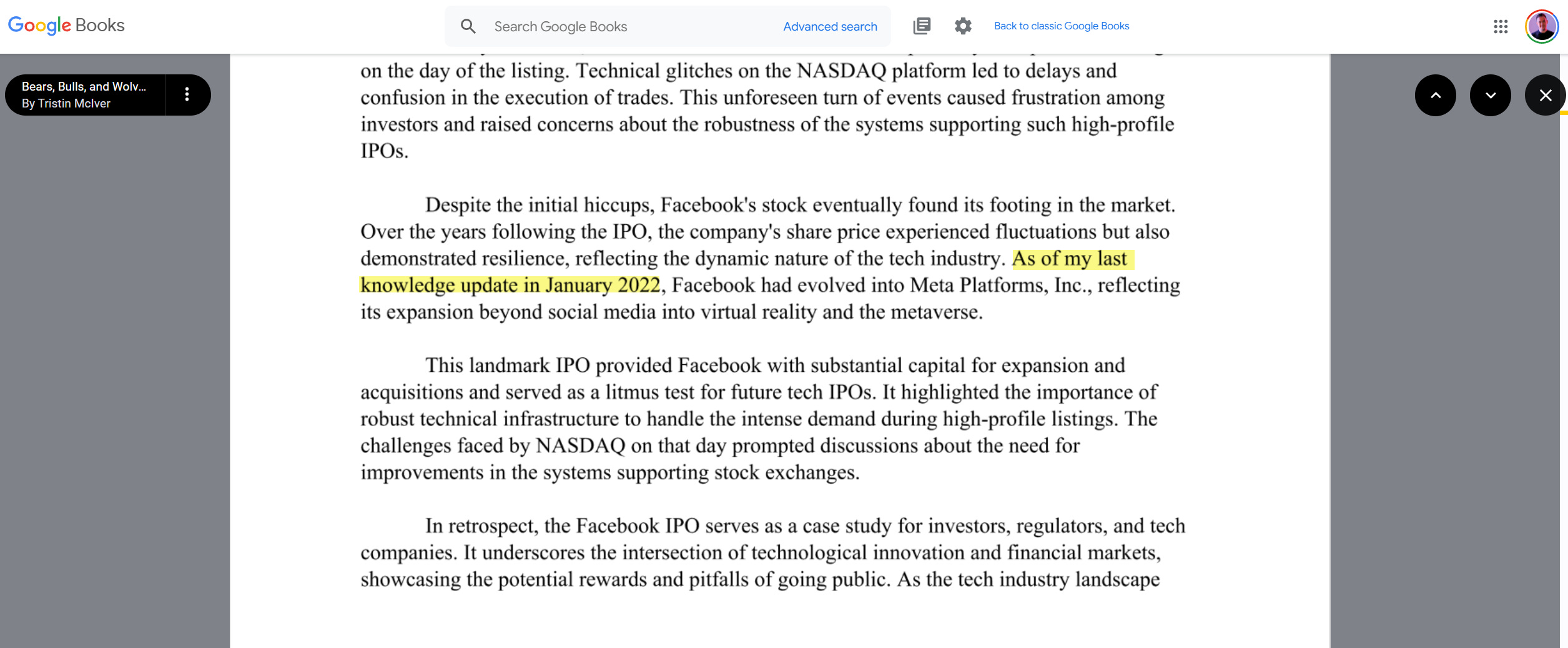 Image Credit: Kevin Indig
Image Credit: Kevin IndigTakeaway
Labels, whether mental or visual, influence our decisions. They annotate the world for us and have the power to create or destroy trust. Like category heuristics in shopping, labels simplify our decision-making and information filtering.
From Messy Middle:
Lastly, the idea of category heuristics, numbers customers focus on to simplify decision-making, like megapixels for cameras, offers a path to specify user behavior optimization. An ecommerce store selling cameras, for example, should optimize their product cards to prioritize category heuristics visually. Granted, you first need to gain an understanding of the heuristics in your categories, and they might vary based on the product you sell. I guess that’s what it takes to be successful in SEO these days.
Soon, labels will tell us when content is written by AI or not. In a public survey of 23,000 respondents, Meta found that 82% of people want labels on AI content. Whether common standards and punishments work remains to be seen, but the urgency is there.
There is also an opportunity here: Labels could shine a spotlight on human writers and make their content more valuable, depending on how good AI content becomes.
On top, writing for AI could be another way to monetize content. While current hourly rates don’t make anyone rich, model training adds new value to content. Content platforms could find new revenue streams.
Web content has become extremely commercialized, but AI licensing could incentivize writers to create good content again and untie themselves from affiliate or advertising income.
Sometimes, the contrast makes value visible. Maybe AI can make the web better after all.
For Data-Guzzling AI Companies, the Internet Is Too Small
Inside Big Tech’s Underground Race To Buy AI Training Data
OpenAI Gives Up On Detection Tool For AI-Generated Text
Labeling AI-Generated Images on Facebook, Instagram and Threads
How The Ad Industry Is Making AI Images Look Less Like AI
How We’re Helping Creators Disclose Altered Or Synthetic Content
Addressing AI-Generated Election Misinformation
China Is Targeting U.S. Voters And Taiwan With AI-Powered Disinformation
Google Books Is Indexing AI-Generated Garbage
Our Approach To Labeling AI-Generated Content And Manipulated Media
Featured Image: Paulo Bobita/Search Engine Journal
Source link : Searchenginejournal.com