
Generative AI, a subset of artificial intelligence, has emerged as a revolutionary force in the tech world. But what exactly is it? And why is it gaining so much attention?
This in-depth guide will dive into how generative AI ****** work, what they can and can’t do, and the implications of all these elements.
What is generative AI?
Generative AI, or genAI, refers to systems that can generate new content, be it text, images, music, or even videos. Traditionally, AI/ML meant three things: supervised, unsupervised, and reinforcement learning. Each gives insights based on clustering output.
Non-generative AI ****** make calculations based on input (like classifying an image or translating a sentence). In contrast, generative ****** produce “new” outputs such as writing essays, composing music, designing graphics, and even creating realistic human faces that don’t exist in the real world.
The implications of generative AI
The rise of generative AI has significant implications. With the ability to generate content, industries like entertainment, design, and journalism are witnessing a paradigm shift.
For instance, news agencies can use AI to draft reports, while designers can get AI-assisted suggestions for graphics. AI can generate hundreds of ad slogans in seconds – whether or not those options are good or not is another matter.
Generative AI can produce tailored content for individual users. Think of something like a music app that composes a unique song based on your mood or a news app that drafts articles on topics you’re interested in.
The issue is that as AI plays a more integral role in content creation, questions about authenticity, copyright, and the value of human creativity become more prevalent.
How does generative AI work?
Generative AI, at its core, is about predicting the next piece of data in a sequence, whether that’s the next word in a sentence or the next pixel in an image. Let’s break down how this is achieved.
Statistical ******
Statistical ****** are the backbone of most AI systems. They use mathematical equations to represent the relationship between different variables.
For generative AI, ****** are trained to recognize patterns in data and then use these patterns to generate new, similar data.
If a model is trained on English sentences, it learns the statistical likelihood of one word following another, allowing it to generate coherent sentences.
Data gathering
Both the quality and quantity of data are crucial. Generative ****** are trained on vast datasets to understand patterns.
For a language model, this might mean ingesting billions of words from books, websites, and other texts.
For an image model, it could mean analyzing millions of images. The more diverse and comprehensive the training data, the better the model will generate diverse outputs.
How transformers and attention work
Transformers are a type of neural network architecture introduced in a 2017 paper titled “Attention Is All You Need” by Vaswani et al. They have since become the foundation for most state-of-the-art language ******. ChatGPT wouldn’t work without transformers.
The “attention” mechanism allows the model to focus on different parts of the input data, much like how humans pay attention to specific words when understanding a sentence.
This mechanism lets the model decide which parts of the input are relevant for a given task, making it highly flexible and powerful.
The code below is a fundamental breakdown of transformer mechanisms, explaining each piece in plain English.
class Transformer:
# Convert words to vectors
# What this is: turns words into "vector embeddings" –basically numbers that represent the words and their relationships to each other.
# Demo: "the pineapple is cool and tasty" -> [0.2, 0.5, 0.3, 0.8, 0.1, 0.9]
self.embedding = Embedding(vocab_size, d_model)
# Add position information to the vectors
# What this is: Since words in a sentence have a specific order, we add information about each word's position in the sentence.
# Demo: "the pineapple is cool and tasty" with position -> [0.2+0.01, 0.5+0.02, 0.3+0.03, 0.8+0.04, 0.1+0.05, 0.9+0.06]
self.positional_encoding = PositionalEncoding(d_model)
# Stack of transformer layers
# What this is: Multiple layers of the Transformer model stacked on top of each other to process data in depth.
# Why it does it: Each layer captures different patterns and relationships in the data.
# Explained like I'm five: Imagine a multi-story building. Each floor (or layer) has people (or mechanisms) doing specific jobs. The more floors, the more jobs get done!
self.transformer_layers = [TransformerLayer(d_model, nhead) for _ in range(num_layers)]
# Convert the output vectors to word probabilities
# What this is: A way to predict the next word in a sequence.
# Why it does it: After processing the input, we want to guess what word comes next.
# Explained like I'm five: After listening to a story, this tries to guess what happens next.
self.output_layer = Linear(d_model, vocab_size)
def forward(self, x):
# Convert words to vectors, as above
x = self.embedding(x)
# Add position information, as above
x = self.positional_encoding(x)
# Pass through each transformer layer
# What this is: Sending our data through each floor of our multi-story building.
# Why it does it: To deeply process and understand the data.
# Explained like I'm five: It's like passing a note in class. Each person (or layer) adds something to the note before passing it on, which can end up with a coherent story – or a mess.
for layer in self.transformer_layers:
x = layer(x)
# Get the output word probabilities
# What this is: Our best guess for the next word in the sequence.
return self.output_layer(x)
In code, you might have a Transformer class and a single TransformerLayer class. This is like having a blueprint for a floor vs. an entire building.
This TransformerLayer piece of code shows you how specific components, like multi-head attention and specific arrangements, work.

class TransformerLayer:
# Multi-head attention mechanism
# What this is: A mechanism that lets the model focus on different parts of the input data simultaneously.
# Demo: "the pineapple is cool and tasty" might become "this PINEAPPLE is COOL and TASTY" as the model pays more attention to certain words.
self.attention = MultiHeadAttention(d_model, nhead)
# Simple feed-forward neural network
# What this is: A basic neural network that processes the data after the attention mechanism.
# Demo: "this PINEAPPLE is COOL and TASTY" -> [0.25, 0.55, 0.35, 0.85, 0.15, 0.95] (slight changes in numbers after processing)
self.feed_forward = FeedForward(d_model)
def forward(self, x):
# Apply attention mechanism
# What this is: The step where we focus on different parts of the sentence.
# Explained like I'm five: It's like highlighting important parts of a book.
attention_output = self.attention(x, x, x)
# Pass the output through the feed-forward network
# What this is: The step where we process the highlighted information.
return self.feed_forward(attention_output)
A feed-forward neural network is one of the simplest types of artificial neural networks. It consists of an input layer, one or more hidden layers, and an output layer.
The data flows in one direction – from the input layer, through the hidden layers, and to the output layer. There are no loops or cycles in the network.
In the context of the transformer architecture, the feed-forward neural network is used after the attention mechanism in each layer. It’s a simple two-layered linear transformation with a ReLU activation in between.
# Scaled dot-product attention mechanism
class ScaledDotProductAttention:
def __init__(self, d_model):
# Scaling factor helps in stabilizing the gradients
# it reduces the variance of the dot product.
# What this is: A scaling factor based on the size of our model's embeddings.
# What it does: Helps to make sure the dot products don't get too big.
# Why it does it: Big dot products can make a model unstable and harder to train.
# How it does it: By dividing the dot products by the square root of the embedding size.
# It's used when calculating attention scores.
# Explained like I'm five: Imagine you shouted something really loud. This scaling factor is like turning the volume down so it's not too loud.
self.scaling_factor = d_model ** 0.5
def forward(self, query, key, value):
# What this is: The function that calculates how much attention each word should get.
# What it does: Determines how relevant each word in a sentence is to every other word.
# Why it does it: So we can focus more on important words when trying to understand a sentence.
# How it does it: By taking the dot product (the numeric product: a way to measure similarity) of the query and key, then scaling it, and finally using that to weigh our values.
# How it fits into the rest of the code: This function is called whenever we want to calculate attention in our model.
# Explained like I'm five: Imagine you have a toy and you want to see which of your friends likes it the most. This function is like asking each friend how much they like the toy, and then deciding who gets to play with it based on their answers.
# Calculate attention scores by taking the dot product of the query and key.
scores = dot_product(query, key) / self.scaling_factor
# Convert the raw scores to probabilities using the softmax function.
attention_weights = softmax(scores)
# Weight the values using the attention probabilities.
return dot_product(attention_weights, value)
# Feed-forward neural network
# This is an extremely basic example of a neural network.
class FeedForward:
def __init__(self, d_model):
# First linear layer increases the dimensionality of the data.
self.layer1 = Linear(d_model, d_model * 4)
# Second linear layer brings the dimensionality back to d_model.
self.layer2 = Linear(d_model * 4, d_model)
def forward(self, x):
# Pass the input through the first layer,
#Pass the input through the first layer:
# Input: This refers to the data you feed into the neural network. I
#First layer: Neural networks consist of layers, and each layer has neurons. When we say "pass the input through the first layer," we mean that the input data is being processed by the neurons in this layer. Each neuron takes the input, multiplies it by its weights (which are learned during training), and produces an output.
# apply ReLU activation to introduce non-linearity,
# and then pass through the second layer.
#ReLU activation: ReLU stands for Rectified Linear Unit.
# It's a type of activation function, which is a mathematical function applied to the output of each neuron. In simpler terms, if the input is positive, it returns the input value; if the input is negative or zero, it returns zero.
# Neural networks can model complex relationships in data by introducing non-linearities.
# Without non-linear activation functions, no matter how many layers you stack in a neural network, it would behave just like a single-layer perceptron because summing these layers would give you another linear model.
# Non-linearities allow the network to capture complex patterns and make better predictions.
return self.layer2(relu(self.layer1(x)))
# Positional encoding adds information about the position of each word in the sequence.
class PositionalEncoding:
def __init__(self, d_model):
# What this is: A setup to add information about where each word is in a sentence.
# What it does: Prepares to add a unique "position" value to each word.
# Why it does it: Words in a sentence have an order, and this helps the model remember that order.
# How it does it: By creating a special pattern of numbers for each position in a sentence.
# How it fits into the rest of the code: Before processing words, we add their position info.
# Explained like I'm five: Imagine you're in a line with your friends. This gives everyone a number to remember their place in line.
pass
def forward(self, x):
# What this is: The main function that adds position info to our words.
# What it does: Combines the word's original value with its position value.
# Why it does it: So the model knows the order of words in a sentence.
# How it does it: By adding the position values we prepared earlier to the word values.
# How it fits into the rest of the code: This function is called whenever we want to add position info to our words.
# Explained like I'm five: It's like giving each of your toys a tag that says if it's the 1st, 2nd, 3rd toy, and so on.
return x
# Helper functions
def dot_product(a, b):
# Calculate the dot product of two matrices.
# What this is: A mathematical operation to see how similar two lists of numbers are.
# What it does: Multiplies matching items in the lists and then adds them up.
# Why it does it: To measure similarity or relevance between two sets of data.
# How it does it: By multiplying and summing up.
# How it fits into the rest of the code: Used in attention to see how relevant words are to each other.
# Explained like I'm five: Imagine you and your friend have bags of candies. You both pour them out and match each candy type. Then, you count how many matching pairs you have.
return a @ b.transpose(-2, -1)
def softmax(x):
# Convert raw scores to probabilities ensuring they sum up to 1.
# What this is: A way to turn any list of numbers into probabilities.
# What it does: Makes the numbers between 0 and 1 and ensures they all add up to 1.
# Why it does it: So we can understand the numbers as chances or probabilities.
# How it does it: By using exponentiation and division.
# How it fits into the rest of the code: Used to convert attention scores into probabilities.
# Explained like I'm five: Lets go back to our toys. This makes sure that when you share them, everyone gets a fair share, and no toy is left behind.
return exp(x) / sum(exp(x), axis=-1)
def relu(x):
# Activation function that introduces non-linearity. It sets negative values to 0.
# What this is: A simple rule for numbers.
# What it does: If a number is negative, it changes it to zero. Otherwise, it leaves it as it is.
# Why it does it: To introduce some simplicity and non-linearity in our model's calculations.
# How it does it: By checking each number and setting it to zero if it's negative.
# How it fits into the rest of the code: Used in neural networks to make them more powerful and flexible.
# Explained like I'm five: Imagine you have some stickers, some are shiny (positive numbers) and some are dull (negative numbers). This rule says to replace all dull stickers with blank ones.
return max(0, x)
How generative AI works – in simple terms
Think of generative AI as rolling a weighted dice. The training data determine the weights (or probabilities).
If the dice represents the next word in a sentence, a word often following the current word in the training data will have a higher weight. So, “sky” might follow “blue” more often than “banana”. When the AI “rolls the dice” to generate content, it’s more likely to choose statistically more probable sequences based on its training.
So, how can LLMs generate content that “seems” original?
Let’s take a fake listicle – the “best Eid al-Fitr gifts for content marketers” – and walk through how an LLM can generate this list by combining textual cues from documents about gifts, Eid, and content marketers.
Before processing, the text is broken down into smaller pieces called “tokens.” These tokens can be as short as one character or as long as one word.
Example: “Eid al-Fitr is a celebration” becomes [“Eid”, “al-Fitr”, “is”, “a”, “celebration”].
This allows the model to work with manageable chunks of text and understand the structure of sentences.
Each token is then converted into a vector (a list of numbers) using embeddings. These vectors capture the meaning and context of each word.
Positional encoding adds information to each word vector about its position in the sentence, ensuring the model doesn’t lose this order information.
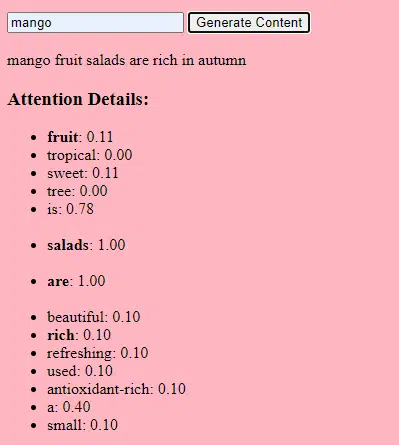
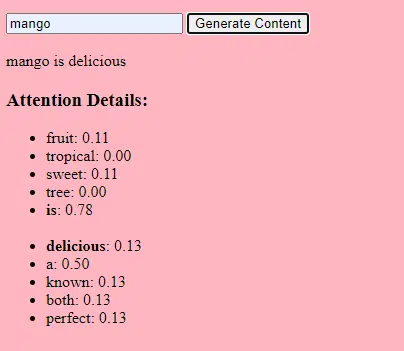
Then we use an attention mechanism: this allows the model to focus on different parts of the input text when generating an output. If you remember BERT, this is what was so exciting to Googlers about BERT.
If our model has seen texts about “gifts” and knows that people give gifts during celebrations, and it has also seen texts about “Eid al-Fitr” being a significant celebration, it will pay “attention” to these connections.
Similarly, if it has seen texts about “content marketers” needing specific tools or resources, it can connect the idea of “gifts” to “content marketers“.

Now we can combine contexts: As the model processes the input text through multiple Transformer layers, it combines the contexts it has learned.
So, even if the original texts never mentioned “Eid al-Fitr gifts for content marketers,” the model can bring together the concepts of “Eid al-Fitr,” “gifts,” and “content marketers” to generate this content.
This is because it has learned the broader contexts around each of these terms.
After processing the input through the attention mechanism and the feed-forward networks in each Transformer layer, the model produces a probability distribution over its vocabulary for the next word in the sequence.
It might think that after words like “best” and “Eid al-Fitr,” the word “gifts” has a high probability of coming next. Similarly, it might associate “gifts” with potential recipients like “content marketers.”
Get the daily newsletter search marketers rely on.
How large language ****** are built
The journey from a basic transformer model to a sophisticated large language model (LLM) like GPT-3 or BERT involves scaling up and refining various components.
Here’s a step-by-step breakdown:
LLMs are trained on vast amounts of text data. It’s hard to explain how vast this data is.
The C4 dataset, a starting point for many LLMs, is 750 GB of text data. That’s 805,306,368,000 bytes – a lot of information. This data can include books, articles, websites, forums, comment sections, and other sources.
The more varied and comprehensive the data, the better the model’s understanding and generalization capabilities.
While the basic transformer architecture remains the foundation, LLMs have a significantly larger number of parameters. GPT-3, for example, has 175 billion parameters. In this case, parameters refer to the weights and biases in the neural network that are learned during the training process.
In deep learning, a model is trained to make predictions by adjusting these parameters to reduce the difference between its predictions and the actual outcomes.
The process of adjusting these parameters is called optimization, which uses algorithms like gradient descent.
- Weights: These are values in the neural network that transform input data within the network’s layers. They are adjusted during training to optimize the model’s output. Each connection between neurons in adjacent layers has an associated weight.
- Biases: These are also values in the neural network that are added to the output of a layer’s transformation. They provide an additional degree of freedom to the model, allowing it to fit the training data better. Each neuron in a layer has an associated bias.
This scaling allows the model to store and process more intricate patterns and relationships in the data.
The large number of parameters also means that the model requires significant computational power and memory for training and inference. This is why training such ****** is resource-intensive and typically uses specialized hardware like GPUs or TPUs.
The model is trained to predict the next word in a sequence using powerful computational resources. It adjusts its internal parameters based on the errors it makes, continuously improving its predictions.
Attention mechanisms like the ones we’ve discussed are pivotal for LLMs. They allow the model to focus on different parts of the input when generating output.
By weighing the importance of different words in a context, attention mechanisms enable the model to generate coherent and contextually relevant text. Doing it at this massive scale enables the LLMs to work the way they do.
How does a transformer predict text?
Transformers predict text by processing input tokens through multiple layers, each equipped with attention mechanisms and feed-forward networks.
After processing, the model produces a probability distribution over its vocabulary for the next word in the sequence. The word with the highest probability is typically selected as the prediction.

How is a large language model built and trained?
Building an LLM involves gathering data, cleaning it, training the model, fine-tuning the model, and vigorous, continuous testing.
The model is initially trained on a vast corpus to predict the next word in a sequence. This phase allows the model to learn connections between words that pick up patterns in grammar, relationships that can represent facts about the world and connections that feel like logical reasoning. These connections also make it pick up biases present in the training data.
After pre-training, the model is refined on a narrower dataset, often with human reviewers following guidelines.
Fine-tuning is a crucial step in building LLMs. It involves training the pre-trained model on a more specific dataset or task. Let’s take ChatGPT as an example.
If you’ve played with GPT ******, you know that prompting is less “write this thing” and more like
- Prompt: Once upon a time
- Continuation: There was an evil wizard at the top of a tower.
- Prompt: Why did the chicken join a band?
- Continuation: Because it had the drumsticks!
To get to ChatGPT from that point involves a lot of low-paid labor. Those people create immense corpora to put a finger on the weight of GPT responses and expected behaviors. These workers create tons of prompt/continuation texts that are like:
- Prompt: Finish this story: “Once upon a time..”
- Continuation: Sure! Once upon a time, in a land far, far away, there was a small village nestled between two majestic mountains.
- Prompt: Tell me a joke about a chicken.
- Continuation: Why did the chicken join a band? Because it had the drumsticks!
This fine-tuning process is essential for several reasons:
- Specificity: While pre-training gives the model a broad understanding of language, fine-tuning narrows its knowledge and behavior to align more with specific tasks or domains. For instance, a model fine-tuned on medical data will better answer medical questions.
- Control: Fine-tuning gives developers more control over the model’s outputs. Developers can use a curated dataset to guide the model to produce desired responses and avoid unwanted behaviors.
- Safety: It helps in reducing harmful or biased outputs. By using guidelines during the fine-tuning process, human reviewers can ensure the model doesn’t produce inappropriate content.
- Performance: Fine-tuning can significantly improve the model’s performance on specific tasks. For example, a model that’s been fine-tuned for customer support will be much better at it than a generic model.
You can tell ChatGPT has been fine-tuned in particular in some ways.
For example, “logical reasoning” is something LLMs tend to struggle with. ChatGPT’s best logical reasoning model – GPT-4 – has been trained intensely to recognize patterns in numbers explicitly.
Instead of something like this:
- Prompt: What’s 2+2?
- Process: Oftentimes in math textbooks for children 2+2 =4. Occasionally there are references to “2+2=5” but there is usually more context to do with George Orwell or Star Trek when that is the case. If this was in that context the weight would be more in favor of 2+2=5. But that context doesn’t exist, so in this instance the next token is likely 4.
- Response: 2+2=4
The training does something like this:
- training: 2+2=4
- training: 4/2=2
- training: half of 4 is 2
- training: 2 of 2 is four
…and so on.
This means for those more “logical” ******, the training process is more rigorous and focused on ensuring that the model understands and correctly applies logical and mathematical principles.
The model is exposed to various mathematical problems and their solutions, ensuring it can generalize and apply these principles to new, unseen problems.
The importance of this fine-tuning process, especially for logical reasoning, cannot be overstated. Without it, the model might provide incorrect or nonsensical answers to straightforward logical or mathematical questions.
Image ****** vs. language ******
While both image and language ****** might use similar architectures like transformers, the data they process is fundamentally different:
Image ******
These ****** deal with pixels and often work in a hierarchical manner, analyzing small patterns (like edges) first, then combining them to recognize larger structures (like shapes), and so on until they understand the entire image.
Language ******
These ****** process sequences of words or characters. They need to understand the context, grammar, and semantics to generate coherent and contextually relevant text.
How prominent generative AI interfaces work
Dall-E + Midjourney
Dall-E is a variant of the GPT-3 model adapted for image generation. It’s trained on a vast dataset of text-image pairs. Midjourney is another image generation software that is based on a proprietary model.
- Input: You provide a textual description, like “a two-headed flamingo.”
- Processing: These ****** encode this text into a series of numbers and then decode these vectors, finding relationships to pixels, to produce an image. The model has learned the relationships between textual descriptions and visual representations from its training data.
- Output: An image that matches or relates to the given description.
Fingers, patterns, problems
Why can’t these tools consistently generate hands that look normal? These tools work by looking at pixels next to each other.
You can see how this works when comparing earlier or more primitive generated images with more recent ones: earlier ****** look very fuzzy. In contrast, more recent ****** are a lot crisper.
These ****** generate images by predicting the next pixel based on the pixels it has already generated. This process is repeated millions of times over to produce a complete image.
Hands, especially fingers, are intricate and have a lot of details that need to be captured accurately.
Each finger’s positioning, length, and orientation can vary greatly in different images.
When generating an image from a textual description, the model has to make many assumptions about the exact pose and structure of the hand, which can lead to anomalies.
ChatGPT
ChatGPT is based on the GPT-3.5 architecture, a transformer-based model designed for natural language processing tasks.
- Input: A prompt or a series of messages to simulate a conversation.
- Processing: ChatGPT uses its vast knowledge from diverse internet texts to generate responses. It considers the context provided in the conversation and tries to produce the most relevant and coherent reply.
- Output: A text response that continues or answers the conversation.
Specialty
ChatGPT’s strength lies in its ability to handle various topics and simulate human-like conversations, making it ideal for chatbots and virtual assistants.
Bard + Search Generative Experience (SGE)
While specific details might be proprietary, Bard is based on transformer AI techniques, similar to other state-of-the-art language ******. SGE is based on similar ****** but weaves in other ML algorithms Google uses.
SGE likely generates content using a transformer-based generative model and then fuzzy extracts answers from ranking pages in search. (This may not be true. Just a guess based on how it seems to work from playing with it. Please don’t sue me!)
- Input: A prompt/command/search
- Processing: Bard processes the input and works the way other LLMs do. SGE uses a similar architecture but adds a layer where it searches its internal knowledge (gained from training data) to generate a suitable response. It considers the prompt’s structure, context, and intent to produce relevant content.
- Output: Generated content that can be a story, answer, or any other type of text.
Applications of generative AI (and their controversies)
Art and design
Generative AI can now create artwork, music, and even product designs. This has opened up new avenues for creativity and innovation.
Controversy
The rise of AI in art has sparked debates about job losses in creative fields.
Additionally, there are concerns about:
- Labor violations, especially when AI-generated content is used without proper attribution or compensation.
- Executives threatening writers with replacing them with AI is one of the issues that spurred the writers’ strike.
Natural language processing (NLP)
AI ****** are now widely used for chatbots, language translation, and other NLP tasks.
Outside the dream of artificial general intelligence (AGI), this is the best use for LLMs since they are close to a “generalist” NLP model.
Controversy
Many users find chatbots to be impersonal and sometimes annoying.
Moreover, while AI has made significant strides in language translation, it often lacks the nuance and cultural understanding that human translators bring, leading to impressive and flawed translations.
Medicine and **** discovery
AI can quickly analyze vast amounts of medical data and generate potential **** compounds, speeding up the **** discovery process. Many doctors already use LLMs to write notes and patient communications
Controversy
Relying on LLMs for medical purposes can be problematic. Medicine requires precision, and any errors or oversights by AI can have serious consequences.
Medicine also already has biases that only get more baked in using LLMs. There are also similar issues, as discussed below, with privacy, efficacy, and ethics.
Gaming
Many AI enthusiasts are excited about using AI in gaming: they say that AI can generate realistic gaming environments, characters, and even entire game plots, enhancing the gaming experience. NPC dialogue can be enhanced through using these tools.
Controversy
There’s a debate about the intentionality in game design.
While AI can generate vast amounts of content, some argue it lacks the deliberate design and narrative cohesion that human designers bring.
Watchdogs 2 had programmatic NPCs, which did little to add to the narrative cohesion of the game as a whole.
Marketing and advertising
AI can analyze consumer behavior and generate personalized advertisements and promotional content, making marketing campaigns more effective.
LLMs have context from other people’s writing, making them useful for generating user stories or more nuanced programmatic ideas. Instead of recommending TVs to someone who just bought a TV, LLMs can recommend accessories someone might want instead.
Controversy
The use of AI in marketing raises privacy concerns. There’s also a debate about the ethical implications of using AI to influence consumer behavior.
Dig deeper: How to scale the use of large language ****** in marketing
Continuing issues with LLMS
Contextual understanding and comprehension of human speech
- Limitation: AI ******, including GPT, often struggle with nuanced human interactions, such as detecting sarcasm, humor, or lies.
- Example: In stories where a character is lying to other characters, the AI might not always grasp the underlying deceit and might interpret statements at face value.
Pattern matching
- Limitation: AI ******, especially those like GPT, are fundamentally pattern matchers. They excel at recognizing and generating content based on patterns they’ve seen in their training data. However, their performance can degrade when faced with novel situations or deviations from established patterns.
- Example: If a new slang term or cultural reference emerges after the model’s last training update, it might not recognize or understand it.
Lack of common sense understanding
- Limitation: While AI ****** can store vast amounts of information, they often lack a “common sense” understanding of the world, leading to outputs that might be technically correct but contextually nonsensical.
Potential to reinforce biases
- Ethical consideration: AI ****** learn from data, and if that data contains biases, the model will likely reproduce and even amplify those biases. This can lead to outputs that are sexist, racist, or otherwise prejudiced.
Challenges in generating unique ideas
- Limitation: AI ****** generate content based on patterns they’ve seen. While they can combine these patterns in novel ways, they don’t “invent” like humans do. Their “creativity” is a recombination of existing ideas.
Data Privacy, Intellectual Property, and Quality Control Issues:
- Ethical consideration: Using AI ****** in applications that handle sensitive data raises concerns about data privacy. When AI generates content, questions arise about who owns the intellectual property rights. Ensuring the quality and accuracy of AI-generated content is also a significant challenge.
Bad code
- AI ****** might generate syntactically correct code when used for coding tasks but functionally flawed or insecure. I have had to correct the code people have added to sites they generated using LLMs. It looked right, but was not. Even when it does work, LLMs have out-of-**** expectations for code, using functions like “document.write” that are no longer considered best practice.
*** takes from an MLOps engineer and technical SEO
This section covers some *** takes I have about LLMs and generative AI. Feel free to fight with me.
Prompt engineering isn’t real (for generative text interfaces)
Generative ******, especially large language ****** (LLMs) like GPT-3 and its successors, have been touted for their ability to generate coherent and contextually relevant text based on prompts.
Because of this, and since these ****** have become the new “gold rush,” people have started to monetize “prompt engineering” as a skill. This can be either $1,400 courses or prompt engineering jobs.
However, there are some critical considerations:
LLMs change rapidly
As technology evolves and new model versions are released, how they respond to prompts can change. What worked for GPT-3 might not work the same way for GPT-4 or even a newer version of GPT-3.
This constant evolution means prompt engineering can become a moving target, making it challenging to maintain consistency. Prompts that work in January may not work in March.
Uncontrollable outcomes
While you can guide LLMs with prompts, there’s no guarantee they’ll always produce the desired output. For instance, asking an LLM to generate a 500-word essay might result in outputs of varying lengths because LLMs don’t know what numbers are.
Similarly, while you can ask for factual information, the model might produce inaccuracies because it cannot tell the difference between accurate and inaccurate information by itself.
Using LLMs in non-language-based applications is a bad idea
LLMs are primarily designed for language tasks. While they can be adapted for other purposes, there are inherent limitations:
Struggle with novel ideas
LLMs are trained on existing data, which means they’re essentially regurgitating and recombining what they’ve seen before. They don’t “invent” in the truest sense of the word.
Tasks that require genuine innovation or out-of-the-box thinking should not use LLMs.
You can see an issue with this when it comes to people using GPT ****** for news content – if something novel comes along, it’s hard for LLMs to deal with it.

For example, a site that seems to be generating content with LLMs published a possibly libelous article about Megan Crosby. Crosby was caught elbowing opponents in real life.
Without that context, the LLM created a completely different, evidence-free story about a “controversial comment.”
Text-focused
At their core, LLMs are designed for text. While they can be adapted for tasks like image generation or music composition, they might not be as proficient as ****** specifically designed for those tasks.
LLMs don’t know what the truth is
They generate outputs based on patterns encountered in their training data. This means they can’t verify facts or discern true and false information.
If they’ve been exposed to misinformation or biased data during training, or they don’t have context for something, they might propagate those inaccuracies in their outputs.
This is especially problematic in applications like news generation or academic research, where accuracy and truth are paramount.
Think about it like this: if an LLM has never come across the name “Jimmy Scrambles” before but knows it’s a name, prompts to write about it will only come up with related vectors.
Designers are always better than AI-generated Art
AI has made significant strides in art, from generating paintings to composing music. However, there’s a fundamental difference between human-made art and AI-generated art:
Intent, feeling, vibe
Art is not just about the final product but the intent and emotion behind it.
A human artist brings their experiences, emotions, and perspectives to their work, giving it depth and nuance that’s challenging for AI to replicate.
A “bad” piece of art from a person has more depth than a beautiful piece of art from a prompt.
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
Source link : Searchengineland.com



