As we encounter advanced technologies like ChatGPT and BERT daily, it’s intriguing to delve into the core technology driving them – transformers.
This article aims to simplify transformers, explaining what they are, how they function, why they matter, and how you can incorporate this machine learning approach into your marketing efforts.
While other guides on transformers exist, this article focuses on providing a straightforward summary of the technology and highlighting its revolutionary impact.
Understanding transformers and natural language processing (NLP)
Attention has been one of the most important elements of natural language processing systems. This sentence alone is quite a mouthful, so let’s unpack it.
Early neural networks for natural language problems used an encoder RNN (recurrent neural network).
The results are sent to a decoder RNN – the so-called “sequence to sequence” model, which would encode each part of an input (turning that input into numbers) and then decode and turn that into an output.
The last part of the encoding (i.e., the last “hidden state”) was the context passed along to the decoder.
In simple terms, the encoder would put together and create a “context” state from all of the encoded parts of the input and transfer that to the decoder, which would pull apart the parts of the context and decode them.
Throughout processing, the RNNs would have to update the hidden states based on the inputs and previous inputs. This was quite computationally complex and could be rather inefficient.
****** couldn’t handle long contexts – and while this is an issue to this day, previously, the text length was even more obvious. The introduction of “attention” allowed the model to pay attention to only the parts of the input it deemed relevant.
Attention unlocks efficiency
The pivotal paper “Attention is All You Need,” introduced the transformer architecture.
This model abandons the recurrence mechanism used in RNNs and instead processes input data in parallel, significantly improving efficiency.
Like previous NLP ******, it consists of an encoder and a decoder, each comprising multiple layers.
However, with transformers, each layer has multi-head self-attention mechanisms and fully connected feed-forward networks.
The encoder’s self-attention mechanism helps the model weigh the importance of each word in a sentence when understanding its meaning.
Pretend the transformer model is a monster:
The “multi-head self-attention mechanism” is like having multiple sets of eyes that simultaneously focus on different words and their connections to understand the sentence’s full context better.
The “fully connected feed-forward networks” are a series of filters that help refine and clarify each word’s meaning after considering the insights from the attention mechanism.
In the decoder, the attention mechanism assists in focusing on relevant parts of the input sequence and the previously generated output, which is crucial for producing coherent and contextually relevant translations or text generations.
The transformer’s encoder doesn’t just send a final step of encoding to the decoder; it transmits all hidden states and encodings.
This rich information allows the decoder to apply attention more effectively. It evaluates associations between these states, assigning and amplifying scores crucial in each decoding step.

Attention scores in transformers are calculated using a set of queries, keys and values. Each word in the input sequence is converted into these three vectors.
The attention score is computed using a query vector and calculating its dot product with all key vectors.
These scores determine how much focus, or “attention,” each word should have on other words. The scores are then scaled down and passed through a softmax function to get a distribution that sums to one.
To balance these attention scores, transformers employ the softmax function, which normalizes these scores to “between zero and one in the positive.” This ensures equitable distribution of attention across words in a sentence.

Instead of examining words individually, the transformer model processes multiple words simultaneously, making it faster and more intelligent.
If you think about how much of a breakthrough BERT was for search, you can see that the enthusiasm came from BERT being bidirectional and better at context.

In language tasks, understanding the order of words is crucial.
The transformer model accounts for this by adding special information called positional encoding to each word’s representation. It’s like placing markers on words to inform the model about their positions in the sentence.
During training, the model compares its translations with correct translations. If they don’t align, it refines its settings to approach the correct results. These are called “loss functions.”
When working with text, the model can select words step by step. It can either opt for the best word each time (greedy decoding) or consider multiple options (beam search) to find the best overall translation.
In transformers, each layer is capable of learning different aspects of the data.
Typically, the lower layers of the model capture more syntactic aspects of language, such as grammar and word order, because they are closer to the original input text.
As you move up to higher layers, the model captures more abstract and semantic information, such as the meaning of phrases or sentences and their relationships within the text.
This hierarchical learning allows transformers to understand both the structure and meaning of the language, contributing to their effectiveness in various NLP tasks.
What is training vs. fine-tuning?
Training the transformer involves exposing it to numerous translated sentences and adjusting its internal settings (weights) to produce better translations. This process is akin to teaching the model to be a proficient translator by showing many examples of accurate translations.
During training, the program compares its translations with correct translations, allowing it to correct its mistakes and improve its performance. This step can be considered a teacher correcting a student’s errors to facilitate improvement.
The difference between a model’s training set and post-deployment learning is significant. Initially, ****** learn patterns, language, and tasks from a fixed training set, which is a pre-compiled and vetted dataset.
After deployment, some ****** can continue to learn from new data they’re exposed to, but this isn’t an automatic improvement – it requires careful management to ensure the new data is helpful and not harmful or biased.
Transformers vs. RNNs
Transformers differ from recurrent neural networks (RNNs) in that they handle sequences in parallel and use attention mechanisms to weigh the importance of different parts of the input data, making them more efficient and effective for certain tasks.
Transformers are currently considered the best in NLP due to their effectiveness at capturing language context over long sequences, enabling more accurate language understanding and generation.
They are often seen as better than a long short-term memory (LSTM) network (a type of RNN) because they are faster to train and can handle longer sequences more effectively due to their parallel processing and attention mechanisms.
Transformers are used instead of RNNs for tasks where context and the relationship between elements in sequences are paramount.
The parallel processing nature of transformers enables simultaneous computation of attention for all sequence elements. This reduces training time and allows ****** to scale effectively with larger datasets and model sizes, accommodating the increasing availability of data and computational resources.
Transformers have a versatile architecture that can be adapted beyond NLP. Transformers have expanded into computer vision through vision transformers (ViTs), which treat patches of images as sequences, similar to words in a sentence.
This allows ViT to apply self-attention mechanisms to capture complex relationships between different parts of an image, leading to state-of-the-art performance in image classification tasks.
Get the daily newsletter search marketers rely on.
About the ******
BERT
BERT (bidirectional encoder representations from transformers) employs the transformer’s encoder mechanism to understand the context around each word in a sentence.
Unlike GPT, BERT looks at the context from both directions (bidirectionally), which helps it understand a word’s intended meaning based on the words that come before and after it.
This is particularly useful for tasks where understanding the context is crucial, such as sentiment analysis or question answering.

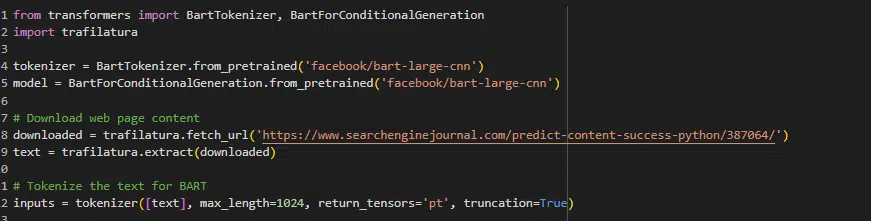
BART
Bidirectional and auto-regressive transformer (BART) combines BERT’s bidirectional encoding capability and the sequential decoding ability of GPT. It is particularly useful for tasks involving understanding and generating text, such as summarization.
BART first corrupts text with an arbitrary noising function and then learns to reconstruct the original text, which helps it to capture the essence of what the text is about and generate concise summaries.
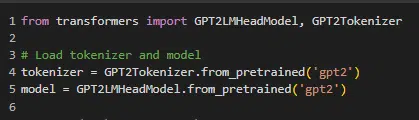
GPT
The generative pre-trained transformers (GPT) model uses the transformer’s decoder mechanism to predict the next word in a sequence, making it useful for generating relevant text.
GPT’s architecture allows it to generate not just plausible next words but entire passages and documents that can be contextually coherent over long stretches of text.
This has been the game-changer in machine learning circles, as more recent massive GPT ****** can mimic people pretty well.
ChatGPT
ChatGPT, like GPT, is a transformer model specifically designed to handle conversational contexts. It generates responses in a dialogue format, simulating a human-like conversation based on the input it receives.
Breaking down transformers: The key to efficient language processing
When explaining the capabilities of transformer technology to clients, it’s crucial to set realistic expectations.
While transformers have revolutionized NLP with their ability to understand and generate human-like text, they are not a magic data tree that can replace entire departments or execute tasks flawlessly, as depicted in idealized scenarios.
Dig deeper: How relying on LLMs can lead to SEO disaster
Transformers like BERT and GPT are powerful for specific applications. However, their performance relies heavily on the data quality they were trained on and ongoing fine-tuning.
RAG (retrieval-augmented generation) can be a more dynamic approach where the model retrieves information from a database to generate responses instead of static fine-tuning on a fixed dataset.
But this isn’t the fix for all issues with transformers.
Frequently asked questions
Do ****** like GPT generate topics? Where does the corpus come from?
****** like GPT don’t self-generate topics; they generate text based on prompts given to them. They can continue a given topic or switch topics based on the input they receive.
In reinforcement learning from human feedback (RLHF), who provides the feedback, and what form does it take?
In RLHF, the feedback is provided by human trainers who rate or correct the model’s outputs. This feedback shapes the model’s future responses to align more closely with human expectations.
Can transformers handle long-range dependencies in text, and if so, how?
Transformers can handle long-range dependencies in text through their self-attention mechanism, which allows each position in a sequence to attend to all other positions within the same sequence, both past and future tokens.
Unlike RNNs or LSTMs, which process data sequentially and may lose information over long distances, transformers compute attention scores in parallel across all tokens, making them adept at capturing relationships between distant parts of the text.
How do transformers manage context from past and future input in tasks like translation?
In tasks like translation, transformers manage context from past and future input using an encoder-decoder structure.
- The encoder processes the entire input sequence, creating a set of representations that include contextual information from the entire sequence.
- The decoder then generates the output sequence one token at a time, using both the encoder’s representations and the previously generated tokens to inform the context, allowing it to consider information from both directions.
How does BERT learn to understand the context of words within sentences?
BERT learns to understand the context of words within sentences through its pre-training on two tasks: masked language model (MLM) and next sentence prediction (NSP).
- In MLM, some percentage of the input tokens are randomly masked, and the model’s objective is to predict the original value of the masked words based on the context provided by the other non-masked words in the sequence. This task forces BERT to develop a deep understanding of sentence structure and word relationships.
- In NSP, the model is given pairs of sentences and must predict if the second sentence is the subsequent sentence in the original document. This task teaches BERT to understand the relationship between consecutive sentences, enhancing contextual awareness. Through these pre-training tasks, BERT captures the nuances of language, enabling it to understand context at both the word and sentence levels.
What are marketing applications for machine learning and transformers?
- Content generation: They can create content, aiding in content marketing strategies.
- Keyword analysis: Transformers can be employed to understand the context around keywords, helping to optimize web content for search engines.
- Sentiment analysis: Analyzing customer feedback and online mentions to inform brand strategy and content tone.
- Market research: Processing large sets of text data to identify trends and insights.
- Personalized recommendations: Creating personalized content recommendations for users on websites.
Dig deeper: What is generative AI and how does it work?
Key takeaways
- Transformers allow for parallelization of sequence processing, which significantly speeds up training compared to RNNs and LSTMs.
- The self-attention mechanism lets the model weigh the importance of each part of the input data differently, enabling it to capture context more effectively.
- They can manage relationships between words or subwords in a sequence, even if they are far apart, improving performance on many NLP tasks.
Interested in checking out transformers? Here’s a Google Colab notebook to get you started.
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
Source link : Searchengineland.com