
Posted by
Mordy Oberstein
How does Google differentiate between good and bad content? It’s a basic question, yet it’s a question that conjures up explanations that belong in 2010, not in the era of machine learning and deeper contextual understanding. So no, Google is not merely adding up all the backlinks a site has and deeming it quality content once a certain quantity of links has been accumulated. Rather, all things considered, Google is doing a very good job profiling content. That is, Google is quite adept and knowing what good content looks and sounds like and what bad content looks and sounds like within a specific vertical.
Here’s how they do it!
How Google Knows Good Content From Bad Content
There are all sorts of theories out there about how Google knows when it’s looking at good content versus bad content. What these theories so often forget is the greatest resource available to Google. That, of course, is the amount of content at its disposal. Think about it for a second. Within any vertical, for any topic you can imagine, Google has an overabundance of content samples at its fingertips. Samples that it could use to get a sense of what good content looks and sounds like and what bad content looks and sounds like.
All Google would need is a baseline of sorts. A set of content within a specific vertical or for a specific topic that is known to be of excellent quality. With that, wouldn’t it be possible to compare any piece of content on a particular topic to that baseline? Surely, for the most part, such a comparison would be a good indicator if a given piece of quality passes muster? I mean, if only Google had a way of doing this at scale?!
I’m, of course, being a bit facetious. Google indeed does have a way to exercise this ability at scale. In fact, what I have described above is a crude outline of how machine learning works and as we well know Google loves machine learning.
So in clear and simple terms:
How does Google know good content from bad? It takes highly authoritative content from highly authoritative sites from specific verticals and trains its machine learning properties to know what good content looks and sounds like for a given topic. That is, Google via machine learning compares its baseline, i.e., content it knows to be of quality, to content from across the web in order to determine what is quality and what is not.
You could argue this is speculatory. To this I say two things:
1) Occam’s Razor. We know Google uses machine learning to understand things from entities to intent. We know that it has the ability to compare and to qualify on a deep level. All I am suggesting is that Google is doing this at the content level itself. It’s not a big leap at all.
2) I’m leading you on a bit (for the sake of making sure you have a foundational understanding that you can use to extend your SEO knowledge – so don’t be mad). John Mueller of Google was asked about this very topic. Here’s what John had to say:
“I don’t know. I probably would have to think about that a bit to see what would work well for me. I mean it is something where if you have an overview of the whole web or kind of a large part of the web and you see which type of content is reasonable for which types of content then that is something where you could potentially infer from that. Like for this particular topic, we need to cover these subtopics, we need to add this information, we need to add these images or fewer images on a page. That is something that perhaps you can look at something like that. I am sure our algorithms are quite a bit more complicated than that.”
That pretty much sums it up. Don’t be distracted where he says, “We need to add these images or fewer images on a page.” That is certainly true. Imagine a recipe site, a lack of images or even a video would definitely be a red flag for the search engine. However, to me, the most important part of that statement is “… if you have an overview of the whole web… Like for this particular topic, we need to cover these subtopics.” He’s telling you Google has a good sense of how a topic should be covered and if it’s not covered appropriately.
The problem is, I could talk about this until I’m blue in the face. It’s very ethereal. The concept could mean so many things. Thus, what I’d really like to do now that we have a conceptual understanding is to take a look at what profiling content may look like.
==> Find out how content marketing and SEO work together
A Hands-On Look at What Google’s Content Profiling Looks Like
I’m a big believer in visual education. Seeing is believing, a picture is worth a thousand words… that sort of thing. If we’re going to take this concept of how Google profiles content and apply it practically, I think we need to form a more concretized notion of what Google sees among the vastness of its content library. That is, what is obvious and transparent to the search engine? What is possibly being picked up on and internalized by the search engine? Simply, what does content profiling look like so that we can make sure our content is sound?
Before I get going. You have to understand, I do not know what parameters Google has set up within its machine learning construct. All I can offer is a crude look at what is most obvious and unavoidable when profiling content. Still, from this, you should not only be able to more concretely understand what Google is doing but be able to walk away with a bit of a plan as to how to better approach content creation.
Let’s get started, shall we?
A Content Profiling Case Study
To get started I’m going to compare various health sites… because everything authority these days relates to Your Money Your Life (YMYL) sites with the health sector sitting at the epicenter of this. Also, health content has its known authorities (i.e., WebMD and the like) which makes seeing the contrast between quality content and poor content a bit easier.
Let’s start off with a keyword, see how some of the more authoritative sites treat the topic, how some of the worst-performing sites treat the topic, as well as some of the content that falls between the two extremes.
To catch a glimpse of how a site treats/relates to a topic I utilized Google’s “Site” operator to see what content is the most relevant on the site for the keyword cancer and diet. When I started comparing the titles of the content I was shown for those sites that are authority superpowers versus those sites known to be problematic a clear contrast became evident.
Before anything else, here is what the SERP for the keyword cancer and diet brought up:
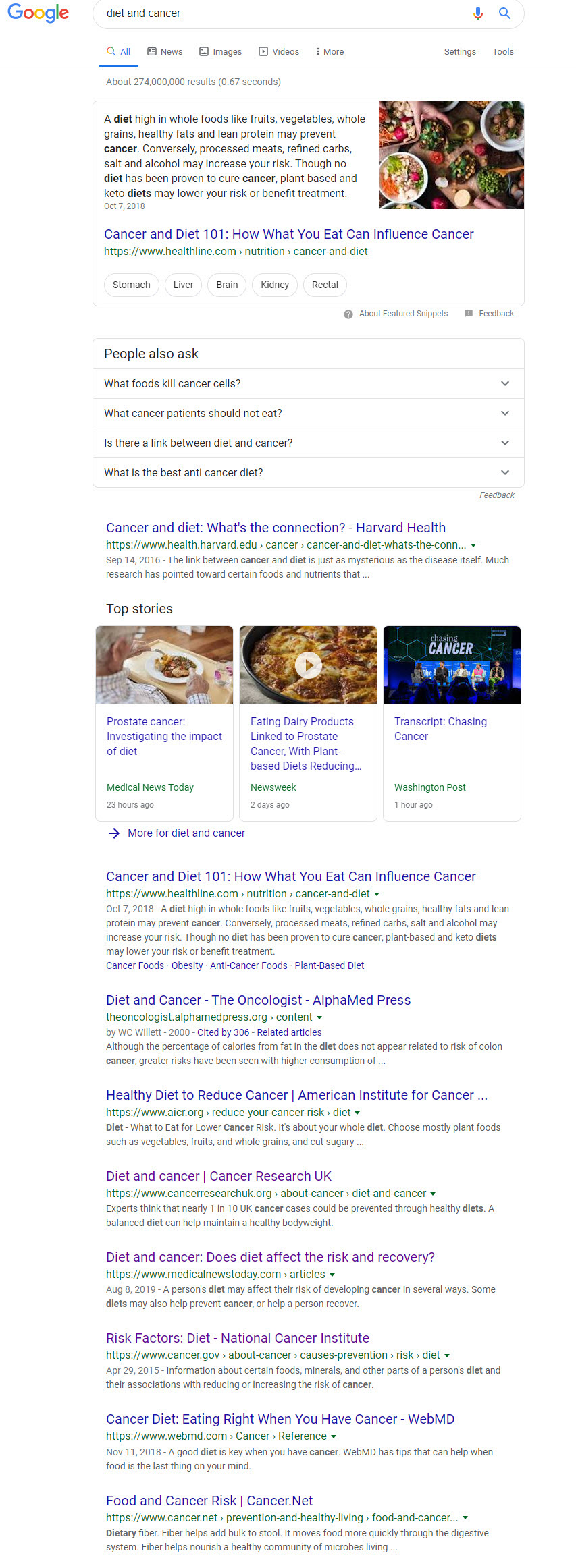
OK, now let me show you the contrast in content that I saw.
Contrasting High Quality & Poor Quality Content
It only makes sense to start with what good content looks like. For this, I’m going to use webmd.com as they not only are one of the most well-ranked sites but they in fact rank for this very query (albeit towards the bottom of page one). In either case, no one would call the site’s authority into question so they are a good place for us to start:
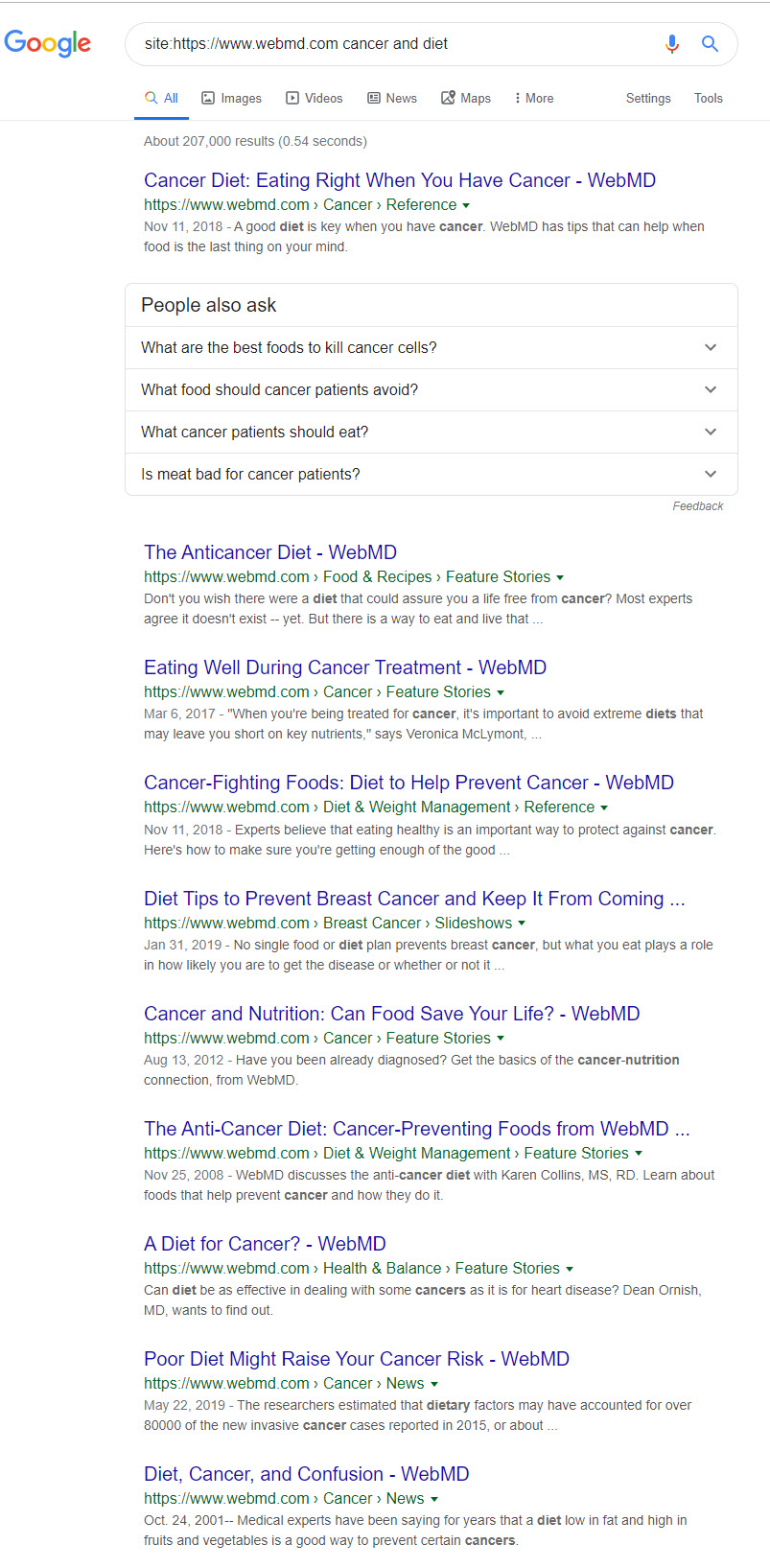
A quick look at the tone and overall construct of the site’s content points to the use of direct and undramatic language. The titles are without any emotionally coercive wording, there is nothing sensational within them, and they are entirely of a highly-informational tone.
Let’s look at another authority that ranks on the SERP for this query, cancer.gov. For the record, cancer.gov is the site for the National Cancer Institute (US), is a part of the NIH, and as should be clear is an official part of the United States government. In our terms, cancer.gov is a super, super, super-authority and here is how they treat the topic of cancer and diet in their titles:
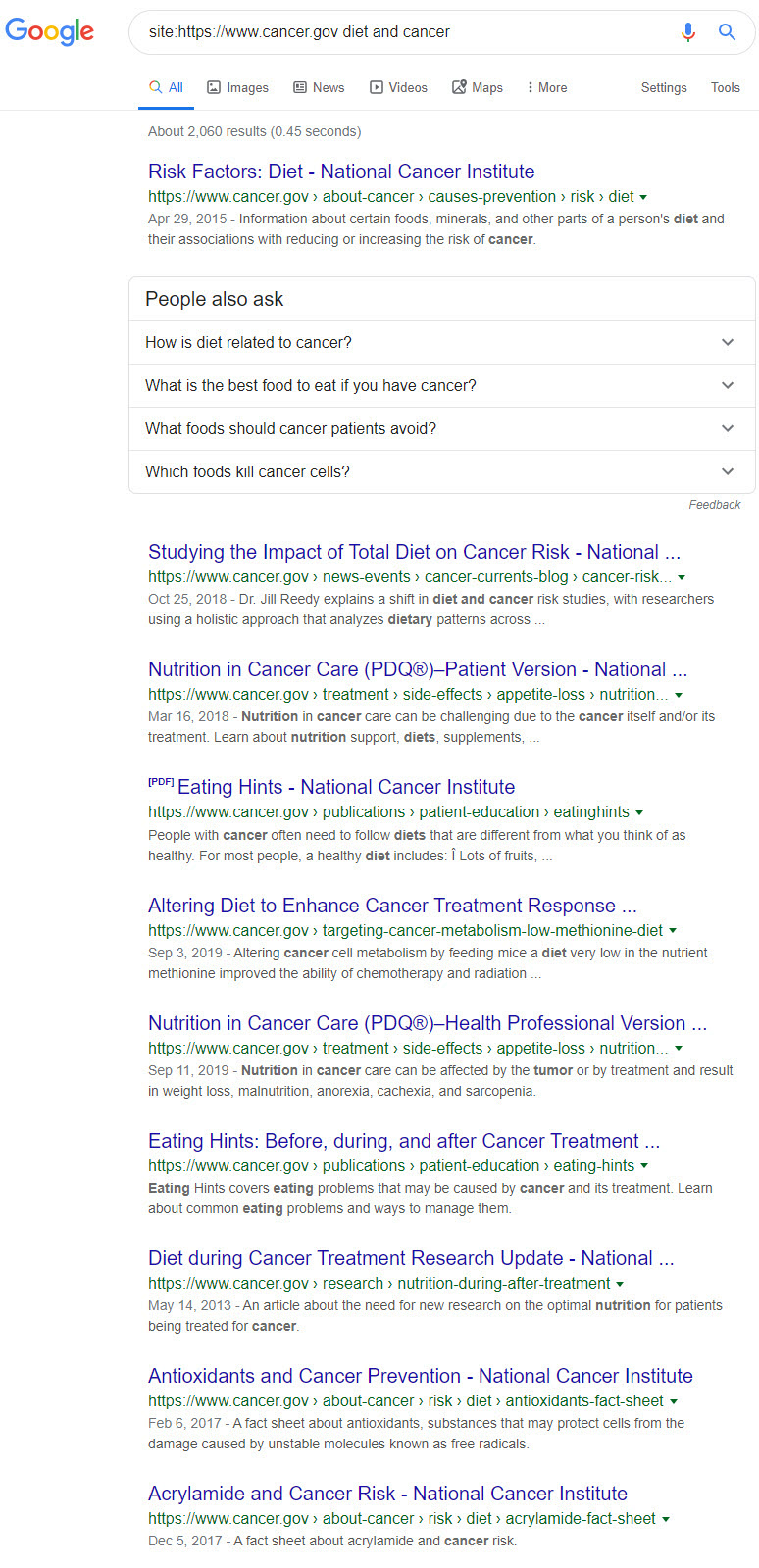
The titles here range from research on the topic to how to go about your diet during cancer treatment. Again, straightforward informational titles free of click-baity sort of phraseology or anything that even hints at causing an emotional reaction on the part of the reader.
Now let’s move on to those sites that Google does not trust. First up is draxe.com who originally fell under my radar when the Medic Update demolished their rankings. Subsequent core updates have also greatly hurt the site. Simply, this is a site that has a trust problem vis-a-vis the search engine. A look at the titles that appear for the keyword cancer and diet may help explain why:
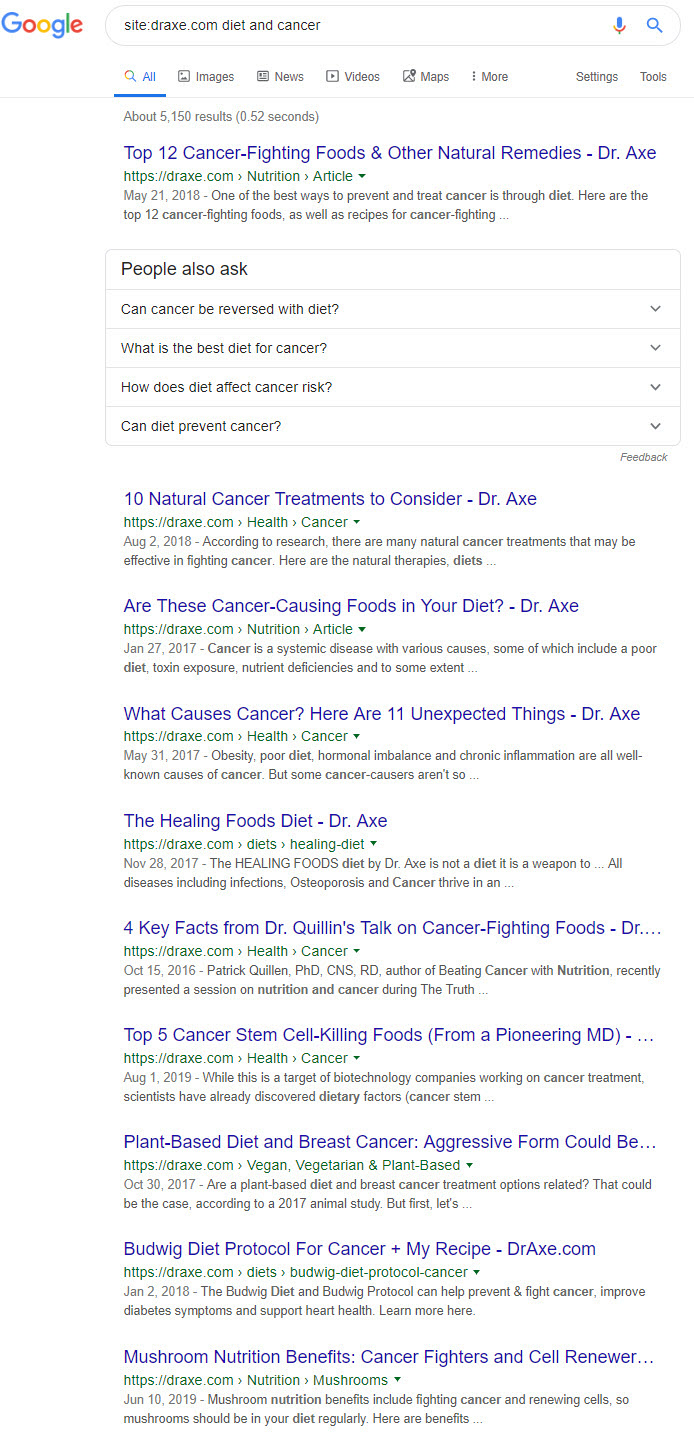
Think back to WebMD and the National Cancer Institute, there were no “top 5 cancer-killing foods.” Those sites preferred direct, to the point, information-driven titles. Not so here. The titles here, by the use of their “numbers,” sound more like a marketing article might sound (such as 10 Ways to Build Your Link Profile… sound familiar?). To put this bluntly, I’m not sure I’m comfortable with the idea of relying on an article to teach me how to eat while undergoing cancer treatment when it sounds like another article filled with typical fluff. I’m pretty sure you aren’t either and I’m definitely sure Google is not as well.
There’s clearly something other than the offering of pure information going on with these titles and their format clearly differs from how our super-authorities approached things.
To accentuate the difference between quality and crap within this vertical let’s move on to a site famous for its poor SERP performance. Mercola.com has been notorious for fairing quite poorly with the core updates. In fact, the title tag the good doctor uses for his home page takes a direct shot at Google’s algorithmic displeasure with his site:

While I do not want to get into the reality of Mercola’s reliability in it of itself (I’m not a doctor, what do I know?), it is clear that Google is not “happy” with what it has found on the site. Which means this is the perfect site to look at for our purposes.
Without for adieu, here’s what the ‘site operation’ gave me for the site using the keyword cancer and diet:
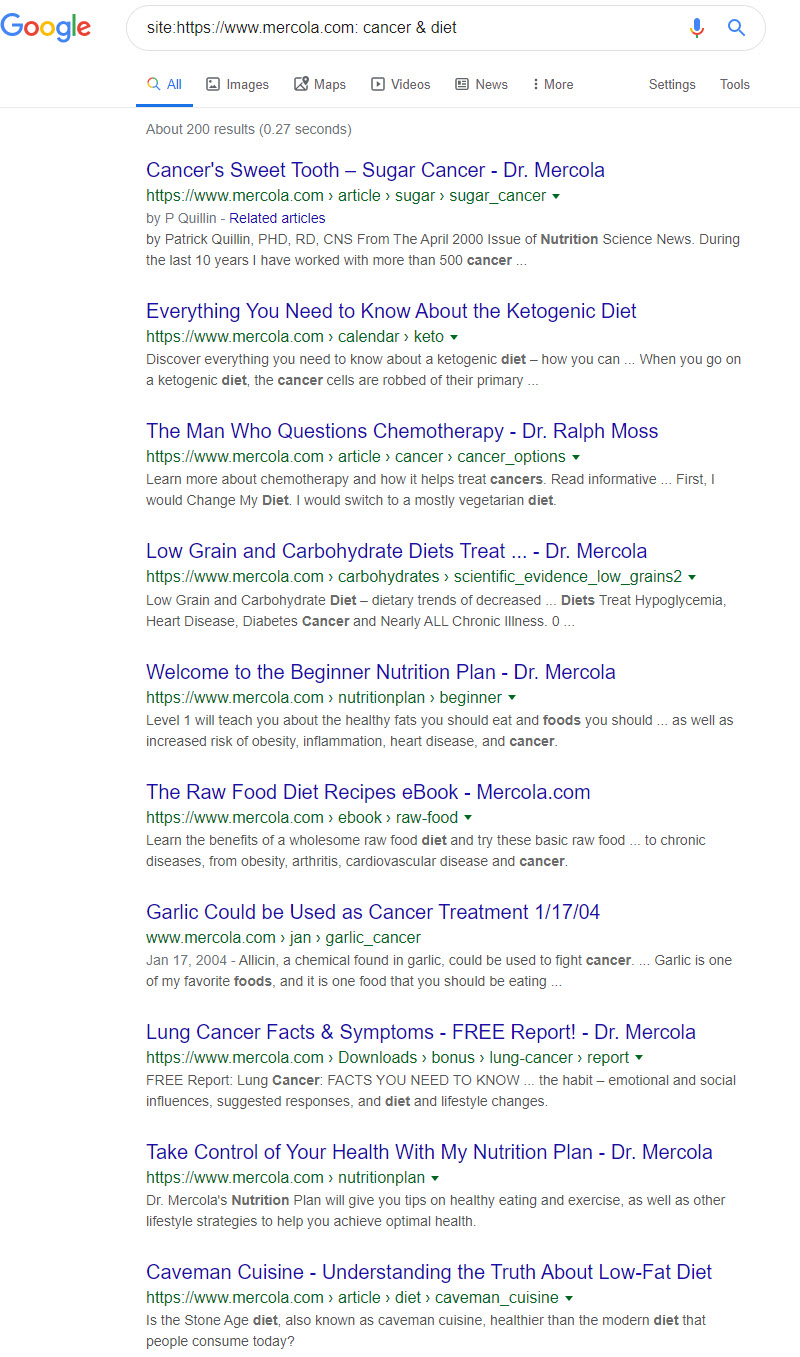
Before proceeding, I implore you to look back at the results produced for WebMD and the National Cancer Institute because the contrast is stark. The title of the first “Mercola” result tells it all. As opposed to being of a more serious and informational tone, we are treated to a linguistic gimmick reminiscent of an essay for 8th-grade science class. “Cancer’s Sweet Tooth,” aside from not telling me much, doesn’t scream authority and safety to me, and clearly it doesn’t to Google either. In truth, the second example is not much better with its use of the ever-cliche “Everything You Need to Know” – again, this could be the title of most articles found on a digital marketing site. Not to beat a dead horse, but the third result is equally horrific, “The Man Who Questions Chemotherapy” hardly sounds like an honest take of chemotherapy’s shortcomings and rings more like an unnuanced rant.
Despite the urge to keep berating the title choices of this site, there’s no need to keep going with this. The contrast between a site like WebMD and mercola.com is about as self-evident of a truth as you’re going to find.
If we can find clear and obvious disparities between an authoritative take on a health topic versus an unreliable take on the topic, surely Google with access to a wide sample of content and machine learning properties can do so and it does. That said, the gap between the good and the bad (and, of course, the ugly) is not always readily transparent.
To see this we have to look no further than the Featured Snippet presented to us on the SERP for cancer & diet:
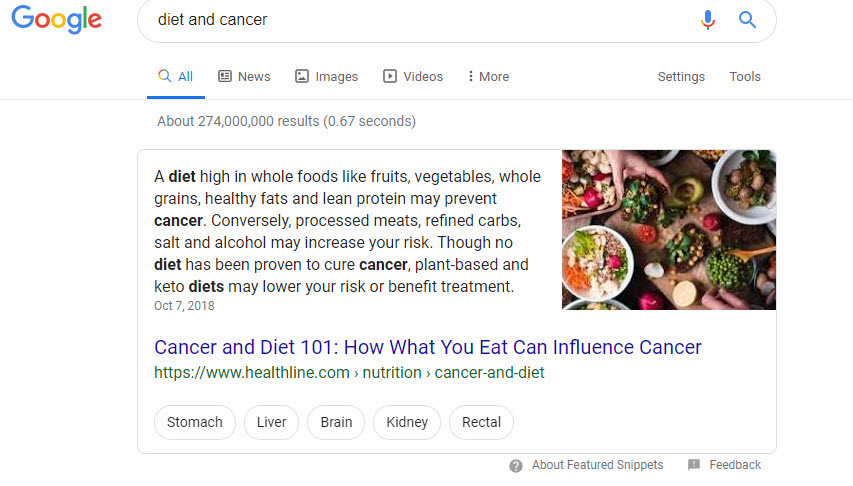
The URL used for the zero-position box doesn’t come from WebMD or the National Cancer Institute, but from healthline.com which has had its share of ups and downs on the SERP.
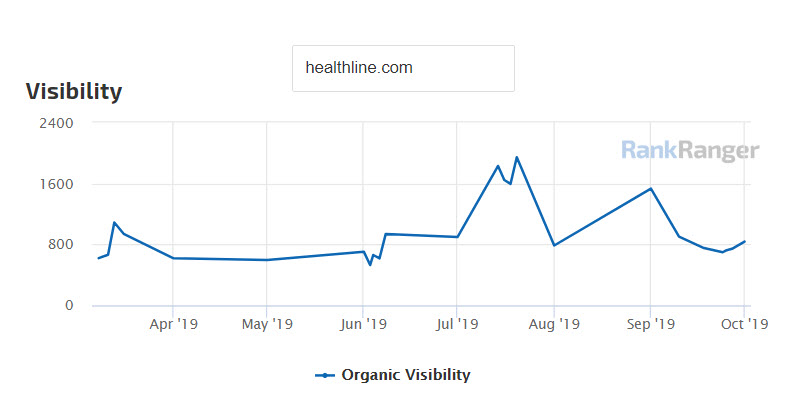
The overall visibility of healthline.com has been subject to volatility that includes various ranking peaks and valleys
Subjecting the site to the same “title analysis” as WebMD et al offers up a bit of a mixed bag:
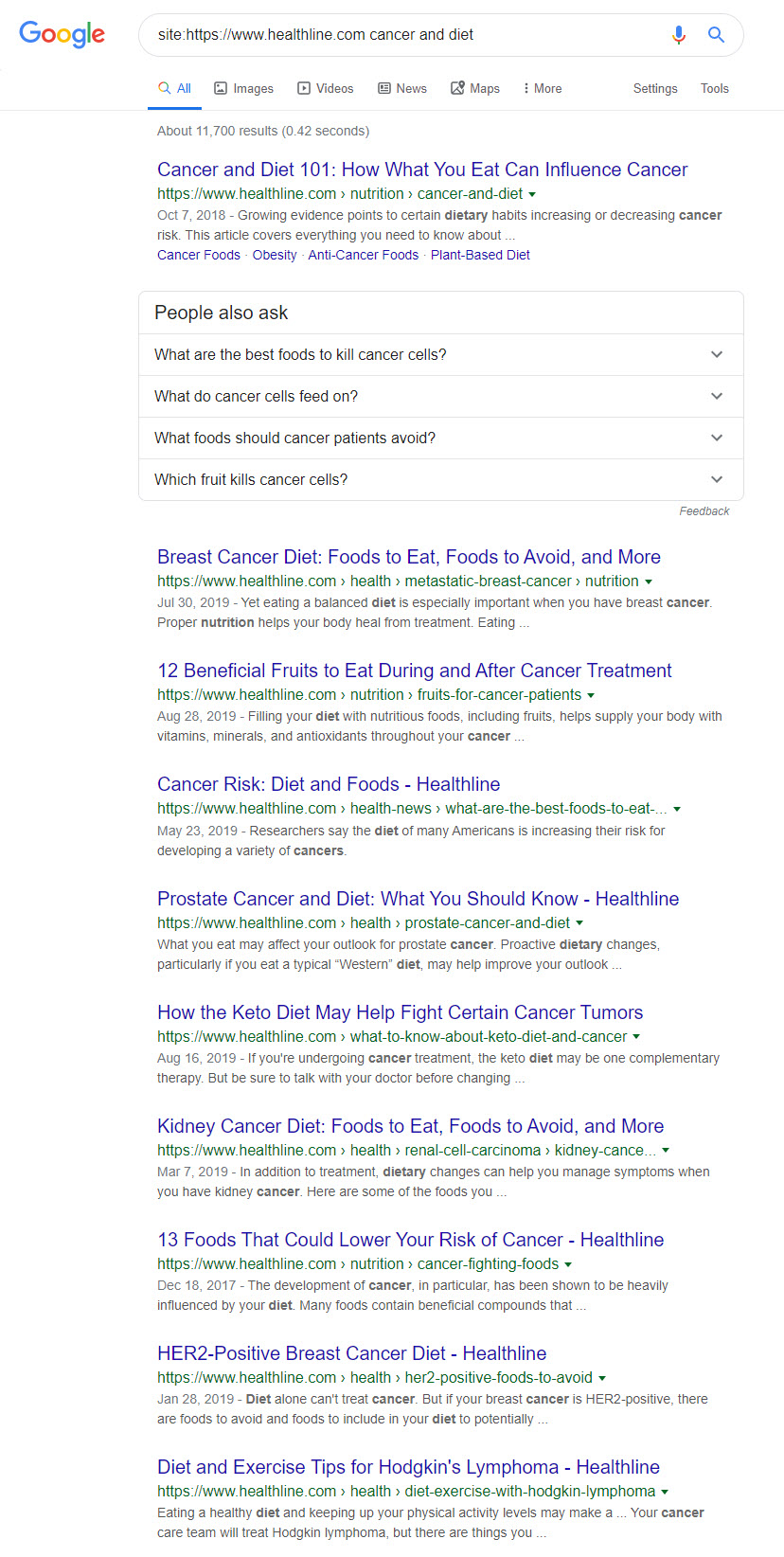
While there are more straightforward and informational titles such as “Breast Cancer Diet: Foods to Eat, Foods to Avoid, and More” you also have your fluff with titles like “12 Beneficial Fruits to Eat During and After Cancer Treatment.”
It just goes to show you how complex, how nuanced, and how murky profiling a site’s content can be. It’s not all “WebMDs” and “Mercolas” – there are a lot of “in-betweens” at play… sites that are not super authoritative in their content format but at the same time are not over the top either. In other words, it’s complicated, which is why you need an advanced machine learning algorithm to profile content in earnest. Beyond that, there’s more to what makes a site rank than the above profiling process (so please don’t accuse me of saying that your content profile is the sole determinant of your rankings). All sorts of factors make their way into the ranking equation that puts a site like healthline.com above webmd.com.
You, Your Site, and Your Content Profile: How to Take Action
So we have a nice understanding of how Google can profile content within a vertical to determine its authoritativeness… how does that help me? Well, having a foundational understanding of what Google can and can’t do and why it does what it does is intrinsically valuable from where I sit. That said, I know the name of the game. If I don’t offer some actionable takeaways “I’ll get put in the back on the discount rack like another can of beans” to quote Billy Joel.
That said, it should be obvious what you should be doing. You should be taking a look at the tone/format of your content relative to the tone/format of the content ranking at the top of the SERP. Are you using language that’s a bit too over the top or “markety” while most of the higher ranking sites go full-on informational?
How do the top-ranking sites approach content for the topic at hand and how does that compare to your take on the topic? Because, clearly, whatever those sites are doing from a content perspective is working. I’m not advocating anything novel here… except that you should leave “keywords” and phraseology per se on the back burner for a moment and take a more inclusive and qualitative look at the top-ranking content on the SERP. This, of course, is not as concrete of a process and is far more abstract of a construct at the same time. That said, analyzing the “flavor” of the content Google prefers goes beyond one page or one piece of content instead of offering an approach to the vertical overall!
A Bird’s-Eye View on Content

Knowing how Google goes about its quest for a better and more authoritative SERP puts you at a real advantage. Most folks still think about “SEO content” at a very granular level. However, as time has gone on Google repeatedly has shown it prefers to take a step back and work towards a basal understanding of content and so forth. At the risk of repeating what I’ve said in other blog posts and episodes of my podcast, the more abstract you get in approaching your site and its content the more aligned you are to how Google itself approaches the web. The more aligned you are to Google the more likely you are to rank well on the SERP.
Simply, it pays to get a bit more abstract in your content analysis and content creation practices. Profiling your content approach to what already works on the SERP is a great (and easy) place to start!
Now that you understand the difference between good quality and bad quality content, check out our guide on how to repurpose old blog content
About The Author




