
Struggling to manage duplicate content on your website? Canonical tags could be the solution you’re looking for. In this comprehensive guide, we’ll explain what canonical tags are and how to use canonical tags to improve your site’s performance on Google as well as other search engines. We’ll also explore different methods for specifying the canonical URL and explain how Google determines the most appropriate ones for each page. Keep reading to learn how to implement canonical tags to bring major SEO benefits to your website.
What is a canonical tag in SEO?
Let’s start with the canonical tag definition.
A canonical tag is a method used to identify the preferred version of a page among duplicate or very similar pages on Google search results. In other words, search engines rely on canonical tags to determine which version of a URL to prioritize. Canonical tags play an essential role in preventing duplicate content issues that may arise when the same content is accessible from multiple URLs.
To ensure proper indexing and visibility in search results, marketers often use canonical URLs. This specific version of the URL serves as the authoritative source, minimizing the risk of duplicate content issues while consolidating ranking signals.
What is a canonical URL?
Now that you have a clear understanding of the canonical tag SEO meaning, you might have the following questions: what is a canonical URL? How does it differ from the canonical tag?
Here’s the answer:
Google defines a canonical URL as the URL of a page chosen (by Google) as the most authoritative among a group of duplicate pages. Simply put, Google recognizes the canonical URL as the “master” version of all other pages displaying duplicate or similar content.
Understanding the canonical URL meaning is crucial for making sure that your website’s content is correctly indexed by search engines. You’ll also need to know it like the back of your hand if you want to avoid duplicate content-related penalties.
How to specify the canonical URL
When a site contains multiple pages with identical or very similar content, search engines may struggle to decide which page to display in SERPs. To tackle this problem, website owners can specify a canonical URL, indicating their preferred page for display.
There are several methods for specifying the master page, many of which are described in more detail in Google documentation. Here, we will go through the most commonly used methods for specifying the canonical URL of a webpage.
Important! Canonical tags are suggestions that Google can easily ignore.
Tags within <head> of HTML
If you want to specify the canonical URL for your page, one common method is to include a rel canonical tag like <link rel=”canonical”> in the <head> section of its HTML code. This straightforward approach is the most widely used and tells search engines which version of your web page should be indexed and displayed when users type in the queries it targets. For example, if two pages on your website contain identical content but have different URLs, adding this line of code can indicate that it is the preferred page to display. Take a look at this canonical tag example:
<head> <link rel="canonical" href=" </head>
Canonical HTTP Response Header
For websites that display dynamic pages based on user input or other variables, adding a canonical URL in the HTTP response header is an effective approach. This method accurately directs search engine crawlers, ensuring that your desired version of the webpage is indexed. For example, you could include this line in the HTTP header:
Link: < rel="canonical"
XML Sitemaps
Another way to specify the canonical URL is by including it in your website’s XML sitemap. This allows you to communicate to search engines which version should be indexed for users’ queries.
Google claims that all pages included in a sitemap.xml file are suggested as canonicals, which can be a solution for large websites but is a weak signal for Google.
How Google chooses the canonical URL
When selecting the canonical URL, Google’s algorithm pays close attention to several key metrics. The following two are the most important:
1. Links pointing to the page: To evaluate a page’s relevance and importance, Google examines any internal and external links pointing to both pages (duplicates) and chooses the page with more links and better quality.
2. Canonical setup (tags, Response Header, sitemap): When determining the dominant version of a page, Google considers whether there are canonical tags embedded in its HTML code, rel=”canonical” HTTP header, among other hints, such as URLs listed on the sitemap.
Additional factors that Google considers when choosing the canonical URL include:
3. HTTPS pages. Google prioritizes HTTPS pages over HTTP pages, except under the following conflict-creating conditions:
- An invalid SSL certificate is present on the secure page.
- There are insecure dependencies (aside from images) included in the protected page.
- Users are redirected to or through an unprotected webpage via its secured counterpart.
- The secure webpage has a rel=”canonical” link pointing to its unsecured version.
4. Hreflang clusters. To ensure that the sites’ localization efforts are successful, Google encourages using URLs within hreflang clusters for canonicalization.
5. Mobile-friendliness. To ensure that the canonical page is indexed correctly, include a rel=”alternate” link element, which references the mobile version of the page if it exists on a separate URL.
Google, as you can see, utilizes a variety of signals to decide which URL should be selected as the canonical one. Normally, if a canonical tag is available, it will use it, but not always. Google might occasionally choose an alternate option if it believes that another page better satisfies user preferences or offers more accurate information.
How to find out which page Google considers canonical
Although the rel=”canonical” element in the HTML code of your pages lets Google know which version has to be canonical, Google can ignore it and choose non-canonical pages instead.
Don’t worry, though! There are several simple methods to determine which page Google considers canonical, including:
- Checking SERPs manually
- Using Google Search Console
- Using SE Ranking’s Rank Tracker
Let’s review them in more detail.
Checking SERPs manually
The first and most straightforward way is to manually review the SERP it is in. Begin by entering the desired keyword or phrase. Look for two variants of your URL in the results (canonical and non-canonical), and note which page Google places higher in the results.
Using Google Search Console
Alternatively, use Google Search Console’s Page Indexing Report to identify the preferred page for search engines if you’ve verified ownership of your website in GSC.
It provides a list of all indexed and non-indexed site pages, allowing you to identify any discrepancies with alternate canonical tags or duplicate content lacking user-selected canonicals. If you see any pages without user-selected canonicals, you can fix this by including the tag on your webpages.

The Performance report provides an overview of your site’s performance in search, including the number of clicks and impressions on each page. If you notice that your non-canonical URLs are attracting attention and receiving impressions during the most recent period of time, it could indicate that Google is disregarding your canonical tags. This situation can even occur when your canonical tags are set up correctly. Sometimes, for example, non-canonical pages receive more backlinks or internal links without any clear reason.
On top of that, Google Search Console’s URL Inspection tool offers real-time updates regarding the indexing and crawling status of any page on your site. With this feature, you can easily identify and address issues related to indexing, canonicalization, or other matters concerning a particular URL.

Using SE Ranking’s Rank Tracker
With the help of SE Ranking’s rank tracking tool, you can get information on the page that Google is paying the most attention to. Check this by going to the Detailed report and hovering over the URL next to your keyword. If you see a number there or if it’s red, something is wrong and Google may not have indexed the page.
To get a bigger picture perspective, export the results into Excel and apply patterns like “=” to see if there are any non-canonical URLs there (for instance, URLs with URM parameters). Then, look into it further to find out why these URLs are getting indexed.
Why are canonical tags important for SEO?
Canonical tags can save your crawling budget and protect your site against duplicate content issues. If you don’t use canonical tags, search engines may waste valuable resources by indexing multiple versions of the same content on different URLs. This can also result in site owners being penalized for duplicate content. To avoid these issues and optimize the use of your website’s crawl budget, it is generally recommended to implement canonical tags wherever possible. By using canonical tags to point out the preferred or primary version of your content, you can ensure that search engines prioritize indexing your most valuable pages. This optimization leads to more efficient use of crawling resources, boosting your rankings and visibility on search engine results for maximum engagement with customers.
Implementing canonical tags also enables you to shield against duplicate content and cannibalization issues. When you have numerous pages competing for similar search queries, this confuses both users and search engines, eventually leading to a decrease in rankings and traffic.
To ensure proper indexing and boost SEO, merge all duplicate content into a single canonical URL by using canonical tags. This will both improve the user experience on the site and enhance your overall SEO strategy, giving you an edge over competitors who are not utilizing this technique.
When should we use the canonical tag for SEO purposes?
Using canonical tags maximizes website performance and can assist you in avoiding duplicate content issues that negatively impact SEO. If you’re a webmaster, following the recommendations provided in this section can help you index your content in the right way so that it’s ranked high by search engines. This will result in improved online visibility and more traffic driven to your page.
Sorting options
It is crucial to utilize canonical tags when implementing sorting options on your website to specify the preferred version of the content. For example, if you have a product page that can be sorted by either price or popularity, you must include canonical tags that point to the original, unaltered URL as the main source.
To better understand this concept, let’s take the laptop category on eBay as an example, which contains laptops for work and is optimized for this keyword cluster. The canonical tag for this page looks like this:
<link rel="canonical" href="https://seranking.com/blog/canonical-tag-guide/https://www.ebay.com/b/Workstation-Laptops-Netbooks/175672/bn_7116632031" />
As you can see, the page is referencing itself.
The navigational features this page offers include:
- Best match (time/price/shipping/distance)
- View type (gallery/list)

Let’s change the view type. The products should now be shown in a list format, and the URL changes to https://www.ebay.com/b/Workstation-Laptops-Netbooks/175672/bn_7116632031?rt=nc&_dmd=1.

Notice how the parameters appear at the end of the URL. These parameters are used to perform sorting options and other operations. An endless number of these pages can be generated depending on the range of sorting options. From a search engine’s point of view, each variation with a new parameter is a separate URL.
If pages with identical or very similar content end up in the index (and most likely with the same <title>), they will compete with each other for rankings, leading to keyword cannibalization and lower rankings.
This issue can be prevented by using canonical tags, which allow you to indicate the main version of the document that you want to appear in the SERP. In the example below, the sorting page has the following canonical:
<link rel="canonical" href="https://seranking.com/blog/canonical-tag-guide/https://www.ebay.com/b/Workstation-Laptops-Netbooks/175672/bn_7116632031" />
This page points to the main version of the document without parameters.
Unoptimized filtering
When a variety of filtering parameters are applied, online store websites can have multiple unoptimized pages for their respective keyword cluster.
When we talk about optimizing for keyword clusters, we mean that the document has:
- a <title> optimized for search queries other than the <title> of the page where the filter was applied.
- a unique and optimized H1 header.
- products filtered according to a specific keyword cluster.
It’s worth noting that the HTML5 standard allows for any level of heading, whereas the discussion of H1 refers to a classic situation within the context of the HTML4 standard.
Carefully consider that one landing page equals one user intent. For example, the Laptops & Netbooks category features filters that create separate pages for different user needs.
By selecting the Workstation filter, we arrive at a separate page https://www.ebay.com/b/Workstation-Laptops-Netbooks/175672/bn_7116632031, which we previously examined.
However, let’s consider a scenario where filters aren’t or can’t be optimized. Suppose we want to view products from two separate brands. In this case, there would be no point in optimizing the page for such requests, since each brand should have its own page. To address this, filtering results can be “hidden” using canonical tags.
Important! The use of canonical tags should be analyzed on a case-by-case basis, taking into account the unique needs of each situation.
Duplicate items
In some popular CMS’s, such as Shopify, a product may contain the full path to the category in which it is located. If you add a product to several categories, it creates duplicated URLs that can negatively impact search engine indexing and rankings. Search engines may interpret these URLs as distinct pieces of content, causing a dilution of the website’s overall ranking potential.
For example, let’s review the following product URLs for an iPhone 12:
The third URL is the preferred one, whereas the first two should point to it as to the main canonical document.
Avoid duplicating URLs whenever possible. From an SEO perspective, it is more effective to link categories directly to the main version of the product as opposed to using canonical tags. This both prevents you from having redirects and optimizes search engine indexing.
UTM tags and tracking parameters
When utilizing UTM tags and tracking parameters, it’s important to be aware that this can create URLs that search engines may misinterpret as duplicate content. To counter this, apply canonical tags to your preferred version of the content, which should not include any UTM tags or tracking parameters. By doing so, you can ensure that your website is indexed correctly.
For example, a URL like may have a version with parameters like page/?fbclid=IwAR3cnDV4ERw24pQNVLTFlwKzchPDA1. A similar link can also be generated in the case of a redirect from Facebook. Canonical would be a great solution in this scenario.
Specifying the main version of the site
If your website is accessible through multiple versions, like HTTP and HTTPS, or with the “www” prefix included or not, you normally need to set up a 301 redirect. This can assist you in avoiding any content duplication issues and in making sure that search engines accurately index and rank each page on your site. In some cases, however, you might want to use canonical tags to define which version should be used.
The variations below, for example, are of four different sites:
You can use canonical to specify the main website version.
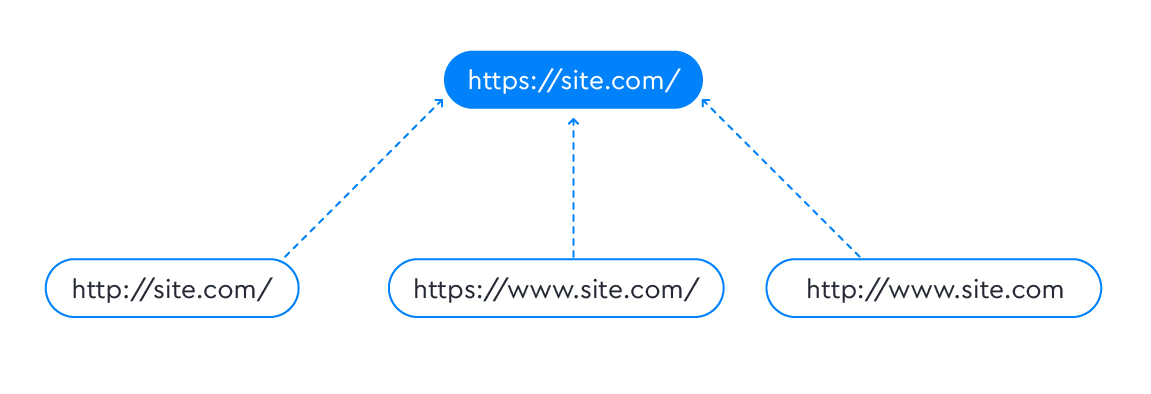
For example, if the main version is , then the rest must contain <link rel=”canonical” href=””>.
When choosing between the HTTP and HTTPS protocols, you should always opt for the latter. To learn why HTTPS is preferable and how to move your site to HTTPS without losing rankings and traffic, read this guide. Also, if you’re having trouble deciding between www and non-www, consult this article.
The canonicalization of cross-domain duplicates
If you are facing duplicate content issues on your website, use cross-domain canonical tags in order to consolidate that content.
Let’s say you have two similar, almost indistinguishable websites, www.example.com and www.my-example.net, with identical content and indexed URLs, www.example/com/page and www.example/net/page.
Even though they are so similar, one website will naturally outshine the other over time if not properly monitored.
To keep these pages on both domains, you need to choose your main content version and then incorporate a cross-domain canonical tag on the copy of your page. Adding this to www.my-example.net/page, for example, will direct search engines to the preferred and original version at www.example.com/page, which will shield you from any duplicate content issues.
Pagination canonicalization
Choosing the most suitable approach to pagination canonicalization can be a complicated task, as opinions on the best method vary greatly.
Option 1: You can take the traditional route and apply self-referencing canonical tags on all pagination pages, which is what Google recommends. This ensures that each page in the series contains a canonical tag that directs back to itself, like in the example below:
catalog/page/2/ contains <link rel="canonical" href="catalog/page/2/" />.
This approach is generally considered safe because it enables web crawlers to reach all pages in the pagination set and correctly index the content. Additionally, this method helps to consolidate link equity across all pages in the series.
Option 2: If you’d prefer to inhibit the indexation of paginated pages, it’s not recommended to canonicalize them because search engines may not respond to your directives. It’s better to use <meta name=“robots” content=“noindex, follow” /> tag instead. This will enable search engines to crawl and follow links on your website but prevent the indexing of any paginated sections.
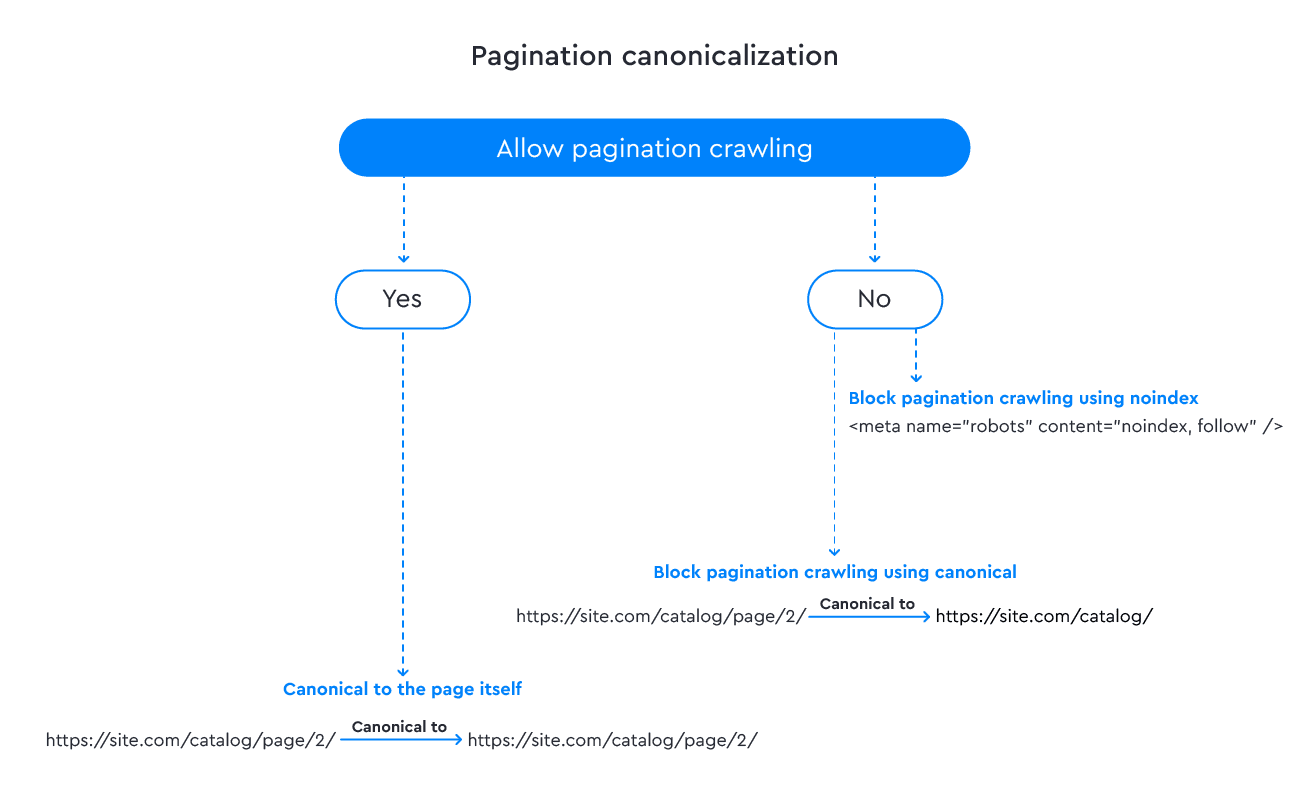
No matter which solution you go with, it is crucial to ensure that the paginated pages are linked properly to their corresponding main content, and that the canonicalization is configured correctly to avoid any potential duplicate content issues.
301 redirect or rel=canonical
Duplicate content can be a real headache for SEO, but there are two simple solutions:
- The 301 redirect
- rel=canonical tag
Both of these methods assist search engines in determining which version of your content should be displayed at the top of organic search results, making it easier to manage duplicate content on your website.
If you need to move content permanently while retaining link equity, the 301 redirect is your best bet. When users or search engine bots attempt to access the old URL, it automatically sends them to the new one, indicating that the original page is no longer valid. This is typically the go-to solution for addressing duplicate content issues.
While a 301 redirect is usually the best choice, there are cases where it may not be feasible or practical. For instance, if you have a paid campaign and use a UTM parameter to track it, you will need both URLs because they both serve different purposes: one for organic performance and the other for paid campaign tracking.
Fortunately, you can still indicate to search engines which version of the content should be prioritized over others by using a rel=canonical tag. This HTML code is embedded in your page header and points to the original source of the content, telling search engine crawlers that all similar versions should be treated as one.
Still, while it’s important to note that a rel=canonical tag can be beneficial in eliminating duplicate content, it doesn’t guarantee that search engines will prioritize the canonical version of your content. Search engines use diverse criteria, such as the presence of external and internal links and the relevance of the content to user searches, to determine which page should appear in SERPs. To ensure that the search engine doesn’t index your non-canonical URLs, use a noindex tag for those pages. This sends a stronger signal to search engine algorithms that these URLs shouldn’t be indexed.
Common mistakes when adding canonical tags
Mistakes can happen even to the most experienced marketers and website owners, and one area where mistakes can negatively affect SEO performance is the addition of canonical tags. When a website has multiple versions of the same content accessible through different URLs, failing to properly implement a canonical tag to indicate the preferred URL can lead to the “Alternative page with proper canonical tag” error. It can eventually lead to duplicate content issues and confusion for search engines, which may struggle to determine which version of the content to index and display in search results. This is the reason why most SEO experts say that you should check canonical URLs regularly and ensure it matches the preferred page for indexing. Read our guide on website audit to learn where to start.
You can use SE Ranking’s Website Audit tool to check all canonical errors and get actionable tips on how to fix them.
In the following section, we’ll delve into the most common mistakes made with canonical tags and provide recommendations to help you prevent them from happening.
Pointing to a URL that is not crawlable or indexable
It’s important to ensure that the chosen canonical URL is crawlable, which means it shouldn’t be blocked in the robots.txt file or by the X-Robots-tag or <meta name=“robots” content=“noindex” />.
You can check if the page is allowed to be scanned and indexed in Google Search Console or by using SE Ranking for your website audits, which can provide a breakdown of all pages and their tags. For a quick check, use our free robots.txt checker to test if your page is open for crawling in your robots.txt file.

Canonizing different types of pages
One typical canonical tag mistake involves canonizing pages with different types of content. For instance, you might mistakenly use a canonical tag for your homepage from one of your blog posts or product pages. This can be confusing for search engines and adversely affect your website’s rankings. To avoid this mistake, make sure to use canonical tags only for identical or similar content on different pages.
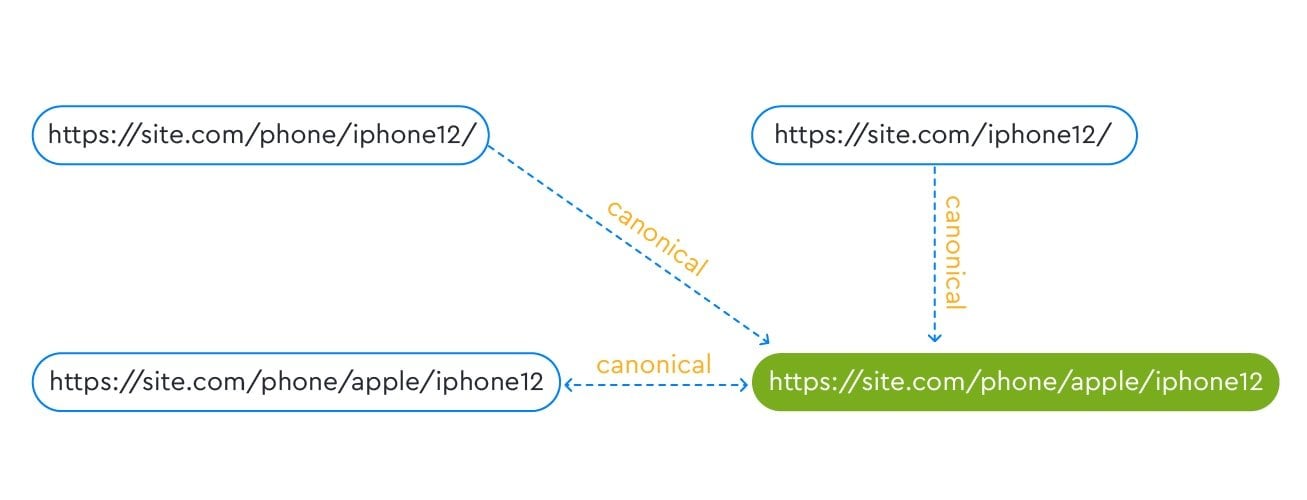
Canonical chains
When typing a URL in the href attribute, make sure that the page you are pointing to does not have a canonical tag pointing to either another page or the same page.
Let’s say, for example, that the page you want to canonicalize is . The page you want to set as canonical is . It already contains the following canonical:
<link rel="canonical" href="" />
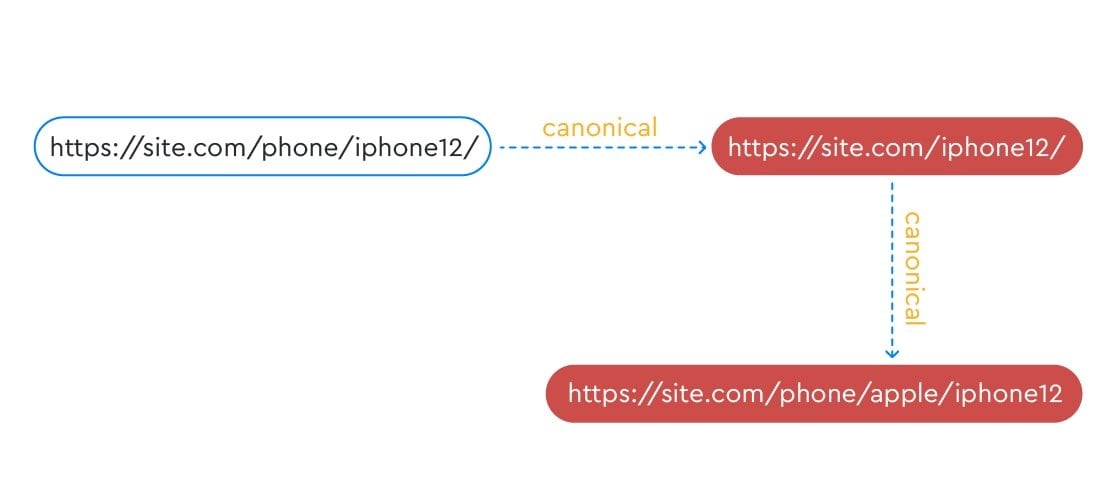
This use case for canonical is incorrect because it creates a canonical chain.
The last in this chain is the page, , which means that it will likely be considered canonical by search engines. If you don’t want to confuse search robots, indicate only one canonical page.
This means, in accordance with our example, that you need to decide which page you want to set as canonical: or .
For the first option, you need to replace canonical on the page so that it points to itself and canonicalizes and .
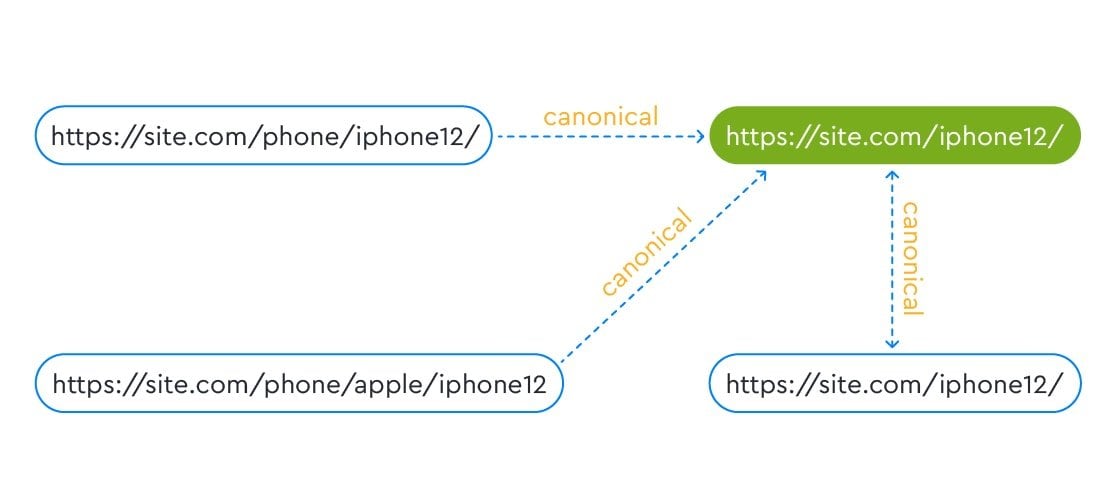
To leave the page phone/apple/iphone12 as canonical, other similar pages must link to it and the page must also link to itself.
Important! Be careful when modifying canonical URLs. Find out why certain values are being used.
Pointing to a URL that returns a status code other than 200
You must make sure that the URL you are designating as canonical returns a status code of 200, not 404 or 301. If search engines do not recognize your website’s canonical tag due to one of these other codes being returned, it could lead to duplicate content issues. To check if the URL you are canonizing functions properly and has a status code of 200, you can use tools like SE Ranking to analyze it.
Pointing to a URL with an invalid protocol
Another common mistake many marketers make is incorrectly specifying the URL protocol. Using HTTP instead of HTTPS, for example, can confuse search engine algorithms and lead to a drop in website rankings. If this happens, and the main version uses the HTTPS protocol, specify the HTTPS version of the page in the href attribute.
Non-canonical pages in the sitemap
One more mistake to be wary of involves adding non-canonical pages in the sitemap.xml. This can cause search engines to ignore the page altogether and index them incorrectly. To avoid this problem, make sure that only main page versions appear in the sitemap. The sitemap file only needs to include the pages pointing to themselves with the help of canonical tags.
Internal links to canonicalized URLs
It is crucial to ensure that your internal links point to the main version of the page, which can strengthen your link equity and aid search engines in crawling through your website without any confusion.
However, there may be cases where you have to choose to link to a canonicalized version of a page. Let’s say, for example, that there are various versions of a page, all belonging to the same category and seen as authentic sources of information. Linking to one of them could help your users access more detailed content or enhance their user experience.
When linking to a canonicalized page, it is essential to ensure that the link is relevant and provides value to visitors. Additionally, you should use the rel canonical tag to prevent any link equity from being passed on to the corresponding page.
Hreflang tags and canonicalized URLs
Another mistake to avoid is using non-canonical URLs in your hreflang tags. Doing so may confuse search engines and result in your non-canonical URLs being indexed and getting impressions in Google. Avoid this mistake by ensuring that your hreflang tags only point to canonical URLs.
Moreover, if you are targeting different language audiences with hreflang elements, it is essential to also designate a canonical page in the same language. If no canonical page exists for that particular language, specify the best possible substitute instead. This step is crucial to help search engines understand your content and index each version of your site for respective languages accurately.
Finally, when it comes to site localization success, Google prefers URLs that are part of hreflang clusters. By utilizing these strategic clusters, you can ensure that your website content is correctly indexed and tailored to the right audience, which leads to greater search engine visibility and an optimal user experience.
The bottom line
Correctly using canonical tags is fundamental to SEO because it prevents duplicate pages and indexing issues from happening. If it’s set incorrectly, however, canonicalization may not bring the desired result and can even lead to lower rankings due to duplicate content.
Follow the best practices described above, but always evaluate each situation individually.
Now it’s your turn! Tell us how you decide when to use a canonical tag on your web pages. What is your experience with implementing canonical tags on your website? Please share your thoughts and insights in the comments section below.



