
What is the dedupe-csv tool?
Available on NPM, dedupe-csv is a command line tool that reads a CSV file, scans for duplicates and exports the unique entries to a new CSV.
Based on Pandas’ drop_duplicates function, it provides a rich set of features with intuitive syntax and the convenience of a command line utility.
How to use dedupe-csv
As with our last NPM module Pivot-Table-JS, make sure you’ve installed Node.js and then add the dedupe-csv package:
npm i -g dedupe-csv
Once installed, the command line tool can be used from the terminal of your choosing, such as command prompt, PowerShell or Node.js command prompt on Windows; and iTerm2 or Terminal on Mac/Linux.
Just refer to the package name, followed by CSV file you wish to deduplicate:
dedupe-csv file="data.csv"
It’s important to note that the file parameter must point to the file relative to where you are currently located within the terminal. For example, if your terminal’s root directory is Documents and your CSV file is in a subdirectory called project, you’ll need to specify the full path:
dedupe-csv file="project/data.csv"
The command will start reading the file, look for identical rows/lines and remove duplicates, leaving you the first duplicate found.
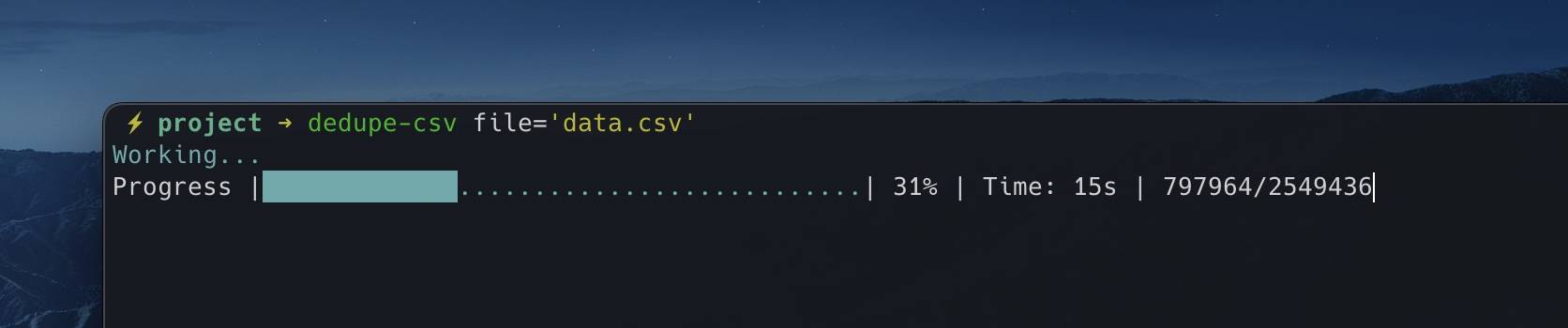
When finished, it will output your results to a new file, keeping the original file unedited.
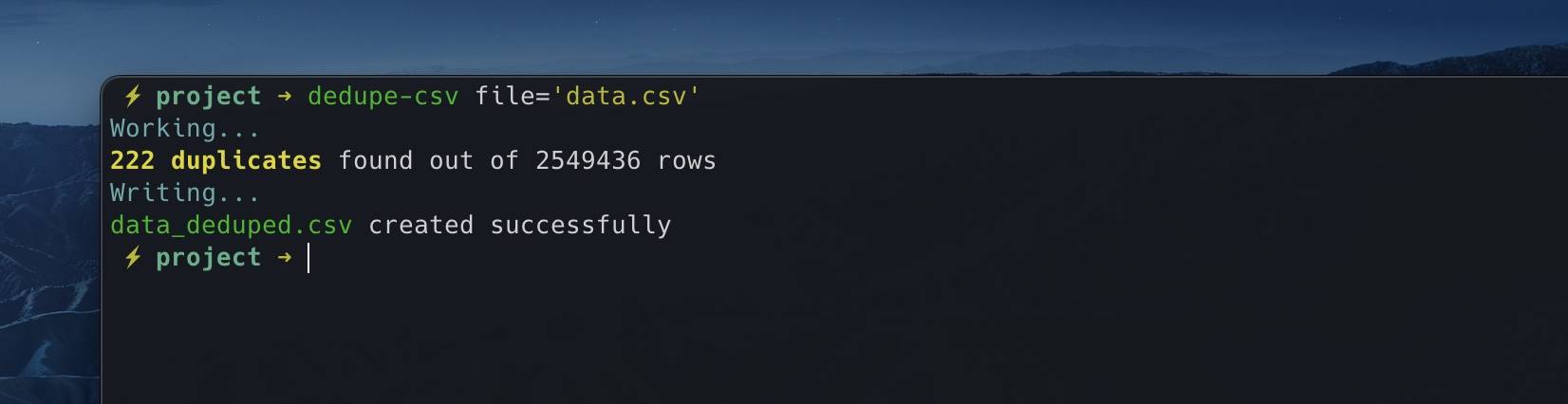
Other options
Remove duplicates by column
If you want to fine-tune the way the tool finds duplicates, you can use the column option to select a specific header (or headers) for the evaluation.
Here, we have a CSV called data.csv, where the brand header has two duplicates, the style header has duplicates on all entries, and rating has no duplicates.
brand,style,rating Yum,cup,1 Yum,cup,2 Foo,cup,6 Foo,cup,8
If we want to check for duplicates within the brand column only, we can run this command:
dedupe-csv file="data.csv" column='brand'
Which will produce a file called data_deduped.csv containing:
brand,style,rating Yum,cup,1 Foo,cup,6
To evaluate based on a sequence of columns, add as many headers as you want, separated by commas.
So given this file data.csv:
brand,style,rating Yum,cup,1 Yum,cup,2 Foo,cup,3 Foo,pack,1 Foo,pack,5
You can enter:
dedupe-csv file="data.csv" column='brand, style'
Which will return:
brand,style,rating Yum,cup,1 Foo,cup,3 Foo,pack,1
Remove duplicates but keep last value
In all these examples, we’ve been keeping the first entry found out of the duplicates. Instead, if we want to keep the last entry, we can specify the keep option.
For example, using this data.csv and command:
brand,style,rating Yum,cup,1 Yum,cup,2 Foo,pack,1 Foo,pack,5
dedupe-csv file="data.csv" column='brand' keep='last'
Will return a data_deduped.csv containing:
brand,style,rating Yum,cup,2 Foo,pack,5
It’s my hope that the SEO and wider digital marketing community find this module a useful addition to their toolkit.
If you have any questions about using the module or want to learn more about how Builtvisible build custom solutions to help businesses maximise their marketing spend, please get in touch.



