

Soundtrack
I had a conversation with my mum a while ago about the new DALL-E ‘thing’ that came out. My mum’s an artist and a writer– not a technophobe or a luddite by any means, but not a developer either. I’m not sure if I imagined the concern in her voice or not, but the tone of the conversation was bleak. The images generated by DALL-E were vivid, and beautiful, and seemed like art.
Well, maybe that’s not fair. Maybe not ‘seemed.’
This blog post is an overview and summary of several different AI topics. I’m writing specifically for audiences unfamiliar with or comfortable with AI, coding, or math. Some of these topics I’m planning on giving deeper dives on their own, but I think we’re kind of at a tipping point here. There’s a new kind of automation on the horizon, and I think it’s important that information about this is accessible and understandable to everyone.
What is AI?
One thing that my mother told me on our call, was: “If you write an explainer blogpost, use ‘AI’ in the title, not ‘ML.’ Nobody knows what ML means.” She might have been exaggerating, but she’s not wrong. Most people refer to AI, even if it’s just talking about Skynet, the Matrix, and so on. ML is a bit more of a mystery to people.
So– what is AI? Well, for one thing, it’s a misnomer.
To understand the phrase ‘Artificial Intelligence,’ you must first be able to define intelligence. This is a bit like saying ‘to understand archery you must first be able to shoot the sun.’ Sure, you’ll probably aim it the right way, but you’re not going to easily hit your target.

What is intelligence? As a stereotype, your brain might first jump to “a guy who can add up numbers very quickly.” Maybe you have some people in mind– Einstein, Newton, Feynman. Maybe you’re aware that your first thoughts are white and western and male, so you also think about Rosalind Franklin or Ada Lovelace. Nevertheless: you probably think about intelligence as a virtue: one tied to being able to think well. After that, peeling back the onion, you probably understand intelligence as a measure of something’s sentience. Do dogs have intelligence? Do bugs?
I’ve used AI in the title of this piece, and I’m using it here, because it’s the popular nomenclature. But in my experience, AI is more of a marketing term than one that people in the ML space use. I myself use “Machine Learning,” as do (as far as I can tell) most engineers, ethicists, and researchers who deal with “can we make robots think.”
A good callout my friend Luke made is to distinguish further between ‘AI’ and ‘AGI.’ AGI, or Artificial General Intelligence, is the kind of… alchemist-turning-lead-into-gold standard for this kind of research. It’s ‘creating a machine that can learn anything a human can’– a generalized artificial intelligence. Part of the problem with using “AI” is that it brings in the implications of AGI– saying “AI” makes users think of AGI, when they’re really dealing with a flawed, specific, ML algorithm.
So what is Machine Learning?
Machine Learning is the term for trying to get machines to figure stuff out without being specifically programmed.
As an example: you have a pile of widgets, and you want to sort them into two piles based on their attributes. A traditional programming approach would do something like ‘if color=red, left, else, right.”
A machine learning approach would be more like “there are x sets of widgets: using the information you have sort these piles.” Depending on how closely you monitor the results, you might get the same end result– or you might get something completely new.
For example, you could train the algorithm by labelling a smaller number of widgets (this is what a blue one looks like, this is what a red one looks like) and then correcting it if it goes off the beaten path. (“This isn’t red, it’s green!”) You could also just put as much data as possible in (this is what the widgets look like these are their differences, these are their similarities) and let the algorithm figure it out. If you have more data (either more labels/descriptions, or just more widgets) you’ll get different results.
One major shift in the landscape of ML has been the ability to use MASSIVE datasets for training: and while the traditional wisdom is “the more data you have, the more accurate your results will be,” the reality is that the more data you have, the more you can train your algorithm to be wrong.

Traditional programming relies a lot on ‘knowns’– you know what’s going in and what you expect to get out of it. The trick is getting a from b. Machine learning relies on bulk information– this is a, this is b, figure it out.
Intelligence vs. thought, thought vs. being. It’s all very philosophical and not very practical. A lot of discussions come down to that one scene from iRobot, you know the one:

So how do Dall-e and GPT work?
Something I’ve often said and read is that good machine learning is bad statistics. If statistics is trying to describe data well by using the right numbers, machine learning is trying to use numbers to get the right descriptions. If you don’t do statistics, that’s the opposite of how it’s supposed to work.
For example: I have a machine count and categorize my widgets. I know I have good numbers, and I expect there to be 50% red widgets. I set my counting machine to count, and get a result of ‘10% red widgets.’ From here, I am at a crossroads: statistics is the practice of updating my earlier assumption, knowing that I have 10% red widgets, not 50% as I started. ML can be fucking around with the inputs until you get the 50% number you were expecting– ‘10% doesn’t seem right, there must be something wrong with the training data.’ (It depends on what you’re using the ML for, though!)
I think one of the ways you can really understand GPT is by running a more simple version yourself. You can do it yourself for free– I **** Max Woolf’s blogpost + code here.
What can we see using this and learning from this code?
For those who don’t click the link: GPT-2 is an earlier version of GPT. Often you will see GPT described as a ‘black box’ because of the complicated, transformers-based ML architecture. It was trained on text that was gathered by looking at Reddit links. So the ML engineers took those links from Reddit (which has its own biases), and cleaned it up somewhat, removing spam and mess. GPT then took that text, and looked for patterns in it. You can then input your own tokens (which is called prompting) or fine tune it further to perform specific tasks.
If you prompt GPT with “Once–” it looks through the patterns it observed from the text it was trained on. Common sentences that start with “once” might be “once upon a time.” But if you had additional text before that (“I was a young child. Once–”) that will change the parameters of the prediction.
Let’s take an example outside of text: I have an ML algorithm that says who will win a World Cup game. It will be affected by the prompts that go in. “France vs. Brazil” will have a different outcome based on weather, starting line up, whether Mbappe is playing, and so on. While the algorithm can’t take into consideration all of those factors, you can update it and give it parameters to play with. If it doesn’t have data about weather, saying “The weather is bad” will not result in changes. But if it has weather data, the weather being bad will affect its prediction of the results.
There are lots of ways to perform ‘machine learning,’ but most of them are ways of looking for patterns in large reams of data and being able to replicate those patterns with new prompts and data sets.
So GPT
GPT is a text model- if you’ve used chat GPT, or other interfaces (the openAI playground was really popular on Tumblr earlier this year), this is the model you’ve played with. GPT is an LLM, or a Large Language Model. And this is where I’m going to underline some words for you. It’s a Language model: it’s a probability distribution. Basically, it guesses, based on the words around it, what the next word in a sentence will be, and it’s very good at that.
But that’s all it’s good at. Like parrots, students before 8am, and dogs, GPT can put up a good act of understanding words, and like the former two cases it may be able to repeat those words or mix them up so they sound good. But that is not the same as understanding.
Humans are fundamentally a social species– we exist to interact with other humans and use their knowledge to augment our own. This means we have a bias towards anthropomorphization – we want to see humanity in other things, even inanimate objects. The problem is that when you bring in an LLM that can plausibly mimic human thought processes, humans have a tendency to overextend them a welcoming hand to the human race.
A Minor Example
Let’s look at an example here.
I’ve asked GPT-3 to write me a paragraph with the prompt: “Please write a paragraph about the human tendency to anthropomorphize non-sentient creatures and how that impulse can cause problems as people begin to interact with LLMs en masse, include citations. “
I’ve cut out some of the response (it was mostly about what anthropomorphizing is with examples about pets,) but this is the money of it:
” This same impulse may also cause issues when people begin to interact with large language ****** (LLMs) en masse. If people begin to anthropomorphize LLMs and ascribe emotions and consciousness to them, it could lead to misunderstandings and potentially harmful interactions. To avoid these problems, it is important for people to be aware of their own tendencies to anthropomorphize and to approach LLMs with a clear understanding of their capabilities and limitations.”

Let’s look at and think about this response to my prompt. In some ways, it’s extremely impressive: it fit the brief (other than not including citations.) But it’s a shallow reading and shallow response: I asked it to write about these problems, and it said “there are problems.” While misunderstandings are slightly more specific, “potentially harmful interactions” is not.
I can ask the LLM to be more specific, and it will be, but this still identifies two problems with LLMs. One is that writing without understanding is fundamentally weak. The second problem is a category, one we will call:
Big Data Problems
LLMs are trained on millions, even billions of pieces of data across the web. This causes the same kinds of problems you get when anything is trained on web data– from machines to human beings. A lot of the stuff on the web is obscene, or offensive, or if it’s not either of those things, it’s bad SEO-laden marketing slop. The internet was designed to bring together the world’s sharpest minds and they created a playground where you get advertised megachurches on sites where *** workers are banned but Pornhub has an account where it tweets tasteless, cheeky, corporate synergy. The web is often sanitized, but not in a way that makes anyone safer; only a way that makes it more boring.

This is the soup that trains these large language ******. Data cleaning is one of the biggest problems that apparently goes unsolved in ML research. This is where you take your data– texts, images, or so on– and clean it up, making it useable, yes, but also making sure you don’t have anything that pollutes your dataset.
Let’s look at a practical example. Amazon, historically, has hired developers primarily from MIT and other big colleges. They created a ML algorithm based on this profile: the algorithm ended up discriminating against perfectly good engineers from historically black colleges.(And women.)
Slurs vs. Slurs (affectionate)
So maybe part of that is cleaning curse words, **** spam, or nonsensical garbage out. But maybe as a step you want to avoid your chatbot becoming a nazi, so you get rid of anything that could be considered offensive to a minority group. But the problem with _that_ is that human language is complex and strange. As an expletive-laden example, see below:
‘**** off you gay bitch’– me to my friends when we get wine drunk and watch the bachelorette.
‘**** off you gay bitch’– the man following me home after pride, screaming at me and throwing bottles
You and I can probably tell which of those is a hate ***** and which is not; but, isolated from context and whirring without human decision-making abilities, it’s almost impossible for a LLM to tell the difference. And that is a problem when you’re talking about the breadth of human experience.
This is a problem that Google has run into historically as well. Using another gay example; for a long time, if you Googled ‘lesbian’, all you’d get is reams of ****. This is one of those instances where I could complain about the way the gay woman exists in a place of fetishization or something, but I’m interested in the problem Google came up against here. Because more people are probably Googling to find pornography than there are lesbians looking for connections. There are probably more horny straight men than lesbian women (especially because lesbians use duckduckgo.) If Google wants to be a happiness engine, well, one response will make more people happy. But if it wants to have the right response, those people will have to do more clicking, or worse, go to another site.
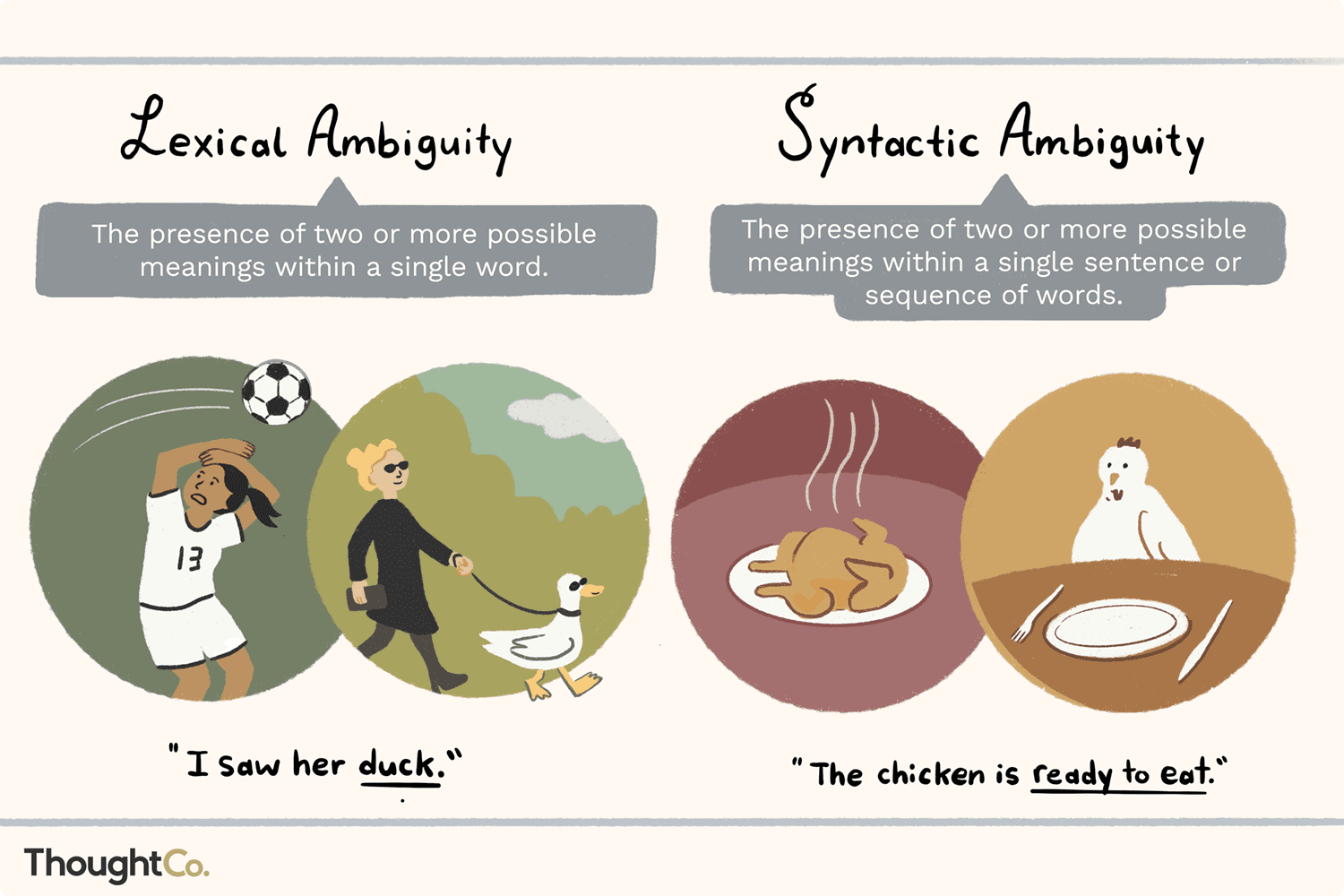
LLMs cannot understand the context of their sentences beyond how they are programmed to: which is to say, semantically. It probably knows based on the large swathes of text it has absorbed that flat Earth is a conspiracy theory; but does it understand that the conspiracy theory is an antisemitic whistle? Context is part of language: and while language ****** have been trained on millions of words and the order of those words they cannot have the context a person who is alive on the earth has.
So TLDR: GPT and other LLMs work by guessing, statistically, what the most likely responses to a prompt are and how likely those words are to be followed by other words. This can lead to some incredible texts, fun experiments, and plausible sentences, but it fundamentally lacks the ability to parse, understand, and argue points. This is all-important to understand as you interact with LLMs and the space around them. I personally think it can be interesting or useful to use these ****** to augment human intelligence: stringing together an outline, writing a summary, and rewriting text. But even in these cases, trying to fake domain knowledge by using GPT is a high-risk effort.
GPT Doesn’t ‘Know’

GPT doesn’t know what the important parts of papers are and it doesn’t know if a paper was researched well or not. It doesn’t know about agendas, meta analysis, or statistical significance.
A few days ago a tweet went around encouraging people to use ChatGPT to summarize a scientific paper about xylitol in a more readable way. All I could think about was Andrew Wakefield, the man who is the epicentre of our current vaccine hysteria. If you were to put his paper in ChatGPT, you’d get an intelligent-sounding, authoritative, uncritical summary, ready to propagate antivaccine propaganda.
A case study that is often brought up for GPT is code– ChatGPT has a code generation feature that was promoted widely. StackOverflow pretty quickly banned GPT-generated code from being used as a response to their questions. Folks on Twitter, especially AI-positive people, quickly said this was StackOverflow trying to muscle out their competition.
But guys.
The GPT code was bad.
It’s pretty okay at common/often written about code challenges, but the second you go off the beaten path it relies on for loops, bad formatting, and TODO statements that would make me blush.
The current level of response from GPT-Chat is amazing. I’ve argued that it is probably about the same level as a low-effort human being. But that’s just it– we already have low effort content out there. Don’t you want to make something good?
DALL-E
Now that we know how GPT works, we can think about DALL-E in that same way. It is simply predicting what it thinks the next pixel over will look like in color, based on training data from thousands of artists who didn’t consent to have their work used in this way.
This is, I think, the middle point between two groups that have the most different points of view about intellectual property rights: for artists, signatures, color marks, and credit HAVE to be everything. While the internet can bring people fame from nothing, it can also mean your work gets all the serial numbers filed off and it ends up on 4chan years later heavily edited as a racist meme.
Developers, on the other hand, praise the almighty MIT license. Sharing code– grabbing it from stackoverflow, using other people’s modules, downloading NPM packages– these are all such major parts of modern web development there’s a joke about everything relying on one package by a guy in Omaha. There’s not often credit, there’s not often fame, and there’s not often rights. There is, however, money, and work, and it’s working so far, right?
It’s a bleak thing: the continued underappreciation of art has led to artworks being used to replace the artists who created them. The result is a model that represents a kind of collective unconscious of art; DALL-E creates beautiful things. (Biased things.)
Steal like an Artist
In 2012, I had a conversation with my mum that I remember vividly. I was watching the United States of Pop 2011 mashup (made by an artist called DJ Earworm) and mum asked if I thought the mashup disrespected the original artists. I replied that I didn’t think so– I thought it was cool that the constituent elements could be brought together to make something new, vibrant, and fun.
In the same way, to some extent, I feel like I cannot muster up the same rage many artists do when they think about DALL-E. I feel that rage when developers and developer fanboys make fun of artists for being upset, denigrate the very art they have built their ****** on and are generally rude and cruel.
But the ability to generate art in seconds, creating a very complicated collage? I can’t hate that. I can’t hate that people who can’t draw can create awesome drawings very quickly, in the same way I can’t hate that photographs replaced portraits, in the same way I can’t hate that pong replaced tennis, in the same way collages, Rothko, and Duchamp’s fountain are or aren’t art.

But it’s always this sort of balancing act, isn’t it? I make digital art: as someone who does that, I have been accused of not making real art: as though I press ‘control paint’ and my image is fully produced and extant with no work of my own.

But now people can do that. GarageBand guitar loops haven’t stopped people from learning the guitar, Wix hasn’t stopped web developers, but it still feels bad to see someone put no effort into something you’ve put effort into and get the same (or more) credit.
I also want to draw a line between using DALL-E and other image-generation platforms for joy and creativity and using it to soullessly automate away the artistic process. There’s a difference between a guy who can’t draw using it to create an image he has in his head or heart and a guy trying to create the most popular #content for the rolling purposes of content creation, or pretending he painted it from scratch.
Part of an ideal world for artists is that they do not have to create corporate coprolith to survive; unfortunately, we are automating away any job that could bring an element of joy or creativity, leaving three classes of Americans: suits, service workers, and slaves.
I don’t think McDonalds’ will ever be fully automated, because part of what people pay for is the human interaction, a person saying “of course, whatever you want” and smiling. Similarly, with these ML leaps forward: there will be some jobs, jobs with people faces, that survive. I cannot say what will happen to the rest. (As one of my editors noted: there are already touchscreens to order in the US. There is already some automation of this kind of job. What does that leave us with?)
DALL-E Problems
Early on, DALL-E got called out for a lack of diversity in their response images. It would return white male doctors for the input ‘doctors,’ and women for the input ‘nurses,’ and so on. Think about it– black writers have been talking for years about a lack of diversity in stock images and what that can reflect about the organization. You scoop in a ton of milk-white doctors and stereotypes about black people from the internet, and you get an image model that reflects that– remember, it’s looking at what the most statistically likely pixel is.
When called out for this, the DALLE team sprung into action– not by fixing inputs or weights, but by stapling words like ‘female’ or ‘black’ to the end of user prompts. This did work– it did result in a more diverse result. But it also meant users could display those stapled words by simpling adding ‘a person holding a sign that says’ to the prompt.
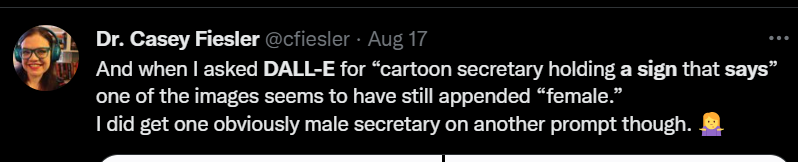

Most software systems are built like this– people are pushed to produce code, and produce it quickly, which leads to quick fixes. Those quick fixes can be more embarrassing/silly than the initial mistake was.
Recycling a ship is always dangerous
Can AI think? Can AI make art?
With all of this comes the big question: can AI think? Can AI create?
My personal answer to this differs from what I have heard from many ML and AI researchers. Most good ML researchers are solidly on the side that LLMs, diffusion ******, and other ML ****** are not sentient and cannot be sentient in the way we define sentient.
I agree with this in most ways: however, this is the caveat I would like to put forward. LLMs are either already sentient, or they will never be.
We already talked about intelligence at the beginning of this very very long piece. Sentience is a related subject: Sentience is, according to Wikipedia, the capacity to experience feelings and sensations. So how do you find out if something is sentient?
The NPC meme is a big one in right-wing circles; it’s a meme I fervently dislike, but it’s useful for explanation purposes. The ‘meme’ goes like this: some people aren’t people, but more like NPCs in a video game. NPCs are ‘Non player characters,’ the characters in a game that aren’t controlled by the player and simply follow computer scripts in their heads. This meme applies that to human people. They believe this means some people have no capacity for individual thought, no feelings– they’re philosophical zombies. They are not sentient.

I bring up this repulsive reference to say we do not know if people are sentient. you can prove humans are sentient, in a bunch of different ways for a bunch of varying definitions within a number of different philosophical schools., but definitively, scientifically, there is no way to know. If someone says “I am sentient” how can they prove it? All we can know is what other people tell us: and it is easy to get an LLM to respond to a prompt saying it ‘feels’ something. You can never objectively prove another human has sentience in a way that can’t also be disproven.
Descartes thought animals were “automatons” and not sentient. Humans are collections of previous experiences and data filtered through several neural networks to make decisions based on probabilities. If you grind a GPU (Graphics processing unit) down to silicon particulate, you won’t find an atom of feeling: if you grind a brain down to its atomic parts, you won’t find feelings there either.
So: LLMs are either already sentient, or they will never be.
But usually, when people talk about sentience, they mean the end of the world scenario– Skynet, Rokos Basilisk, and other extremely serious and non-silly threats!
The thing is: the tools are already being used for evil, cruel purposes. Humans are using AI to hurt each other in the present. The number of things that would need to go catastrophically wrong for AI to be any more dangerous than most other threats is kind of ridiculous. Google has an AI on a supercomputer: how is that thing going to get its hands on nukes?
No, the problems you need to keep an eye on with ML are the ones where it exaggerates and multiplies the problems that already exist.
ML is not dangerous, in of itself. It is when it is used carelessly, or by bad actors, that the harm comes in. ML is not likely to decide the best way to create world peace is to kill all humans: it is likely to show venture capitalists where to buy up houses to make the most money, exacerbating the housing crisis.
Copilot wrote these last few lines: “It is likely to show advertisers where to target people to make the most money, exacerbating the wealth gap. It is likely to show police where to target people to make the most money, exacerbating the prison industrial complex.”
Yeah, buddy. You got it.
Specific questions + misconceptions
(I’ll update this over time as I get questions or requests for clarification.)
- What is GPT?
GPT is a large language model that uses neural networks and transformers to guess at what the most likely words in a sentence will be.
- What is DALL-E?
DALL-E is a model that uses something called Stable Diffusion to generate images, predicting on what the most likely position of pixels is compared to other pixels for the prompt
- What should I use GPT for?
Some automation (getting tokens/keywords, basic automation of summaries, getting data from unstructured data), prompting you if you get stuck writing, coming up with ideas, having fun.
- What should I avoid using GPT for?
Avoid letting GPT think for you.
- Is it AI?
Artificial Intelligence is a kind of computer science boogyman/buzzword. You’ll get less hype if you talk about ML, but it’ll be more accurate.
- Can ML replace humans in creative endeavours?
Yes, but it will be worse at it.
Thanks to the folks who read/edited this (and offered to) before it went out: my friend Clare, my editor Ellie, Alex, Iman, Dáre, Mats, Luke, and Marco.
Related/Sources
Since you’re here… If you can spare 5 bucks, and enjoy my work,I’d appreciate it if you donate a bit of money to the Sylvia Rivera Law Project. Thanks!
Originally Published on Jess Peck’s Blog: https://jessbpeck.com/posts/artificialintelligence/


