Older than most of the search engines we use today, the robots.txt file is a dinosaur of the web. Although there are many articles discussing the protocol and how to use the file, in this post we will cover some ambiguities, corner cases and other undocumented scenarios.
Why should you care?
The robots.txt is a convenient, yet complex tool for SEO that can easily cause unexpected results if not handled carefully. While it makes sense to avoid any typos and ambiguous or conflicting rules when using Allow and Disallow directives, we should also know how search engines behave in these situations.
robots.txt: the puffer fish of the web
robots.txt is like a puffer fish: delicious, yet toxic. It is safe to eat as long as the SEO chef knows how to cook it. They know the file format, the syntax and the rules of grouping. They understand the order of precedence for user-agents and how URL matching based on path values works.
The Robots Exclusion Protocol (REP) is celebrating 25 years and its specification is finally being formalized with some new rules. Yet, we can still observe misuse and confusion in the SEO and webmaster communities, which, unfortunately, result in sub-optimal performance in search for some websites.
So, let’s clarify and expand on some specific puzzling rules.

- The trailing wildcard is ignored
- The order of precedence for rules with wildcards is undefined
- The path value must start with ‘/’ to designate the root
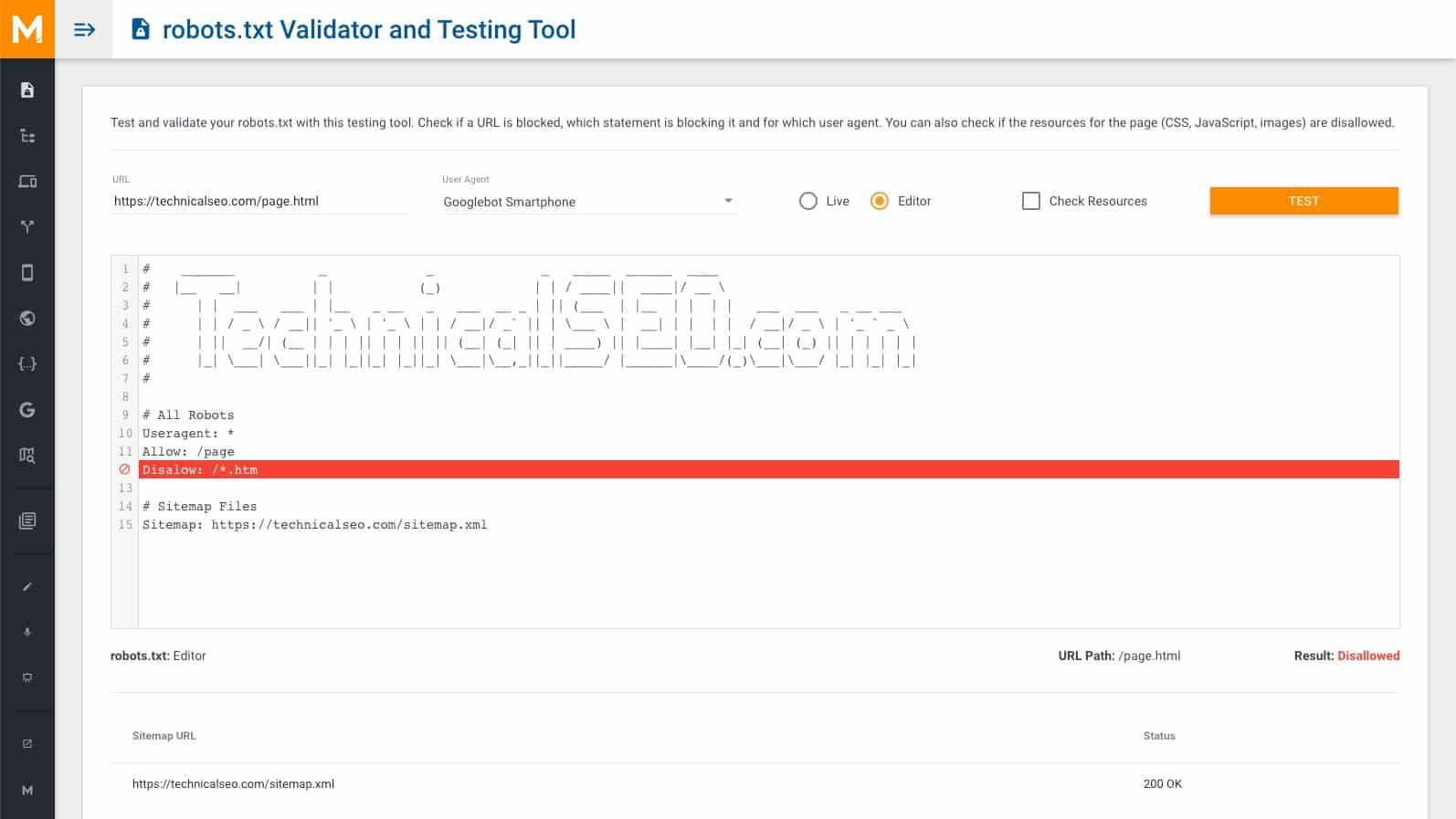
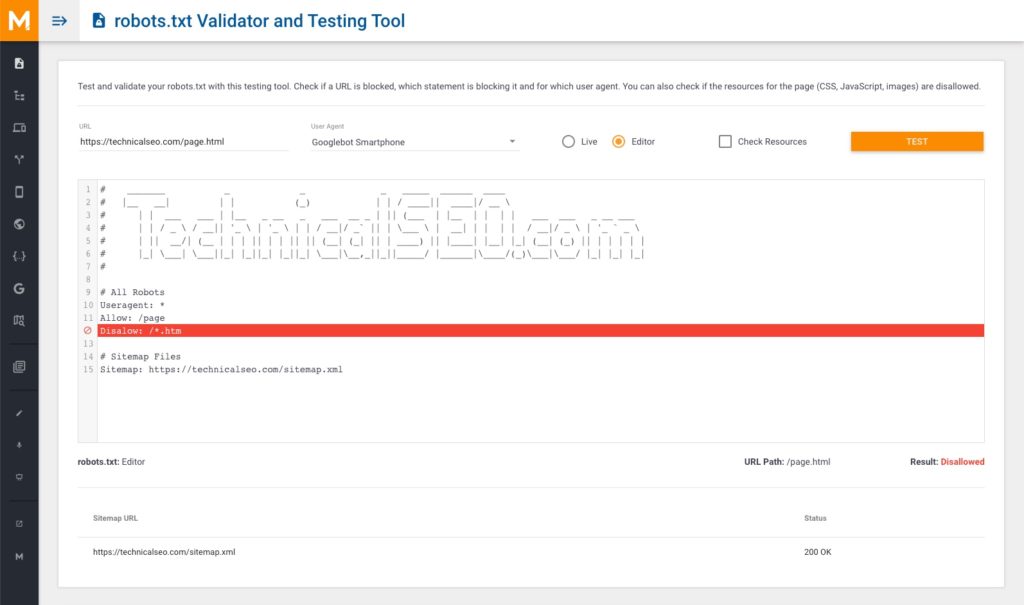
- Google doesn’t support the handling of
<field>elements with simple errors or typos
Quick note before we start: some screenshots in this post show our robots.txt validator and testing tool, which was build based on the original robots.txt documentation and behaves like the following tools and libraries (also used in our research):
In addition to those tools we’ve also used Baidu’s robots.txt Tester, and confirmed the results of our tests on live URLs (crawled or not) with server log files.
1) The trailing wildcard is ignored
According to Google’s robots.txt specifications, the trailing wildcard is ignored.

But is it, really? Well, yes and no. It is “ignored” in that sense that there is an “implicit” * wildcard at the end of every path that is not ending with $ (which is the other wildcard that explicitly designates the end of the URL).
Therefore, /fish = /fish* when it comes to simply matching the URL with the path.
However, the trailing wildcard is not ignored when totaling the path length. This becomes important when Disallow and Allow rules are used concurrently, and while different, they both match a particular URL (or set of URLs).
The length of the path is extremely important as it
determines the order of precedence when multiple lines (rules) match the URL.

In the example above, the URL would be blocked from crawling
since the Disallow statement is longer than the (also matching) Allow directive.
In the specification, Google states that “in case of conflicting rules […] the least restrictive rule is used.” In other words, if both matching paths have the same length, the Allow rule will be used.
As seen in an example in Google’s documentation…

… and clearly stated in the REP draft.
Now, back to our trailing wildcard. If one were to be appended to the “losing” statement in our previous examples, the verdicts would be different.

With the trailing wildcard, the path for the Allow directive is now as long as the path for the Disallow rule, and therefore takes precedence.

With the trailing wildcard, the path for the Disallow directive is now longer and so is being used, as the trailing wildcard is not “ignored” when determining the most “specific” match based on length.
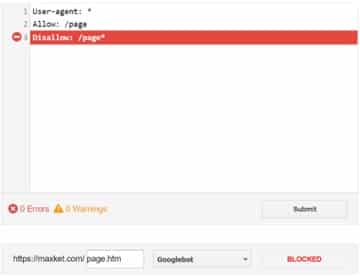
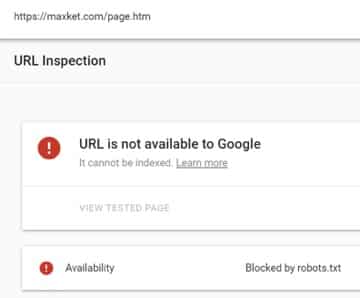
2) The order of precedence for rules with wildcards is undefined
Google’s documentation used to state that “the order of precedence for rules with wildcards is undefined”.

While that statement has been removed in a recent update of the documentation (July 2019), one of the sample situations still shows “undefined” as the verdict.

What does “undefined” mean for Googlebot? As far as we know, a URL can or cannot be crawled. In this situation, is /page.html allowed or disallowed?
As it turns out and according to the tools at our disposal, including Google’s own parser library, nothing is “undefined”. The most specific rule is used.

And in case of conflicting rules, the “least restrictive” rule (e.i. Allow) is used.

3) The path value must start with ‘/’ to designate the root
While the documentation also states that “the path value must start with ‘/’ to designate the root”, paths starting with the ‘*’ wildcard are also taken into consideration.

Such paths, however, lose a little bit in strength due to the missing character.

4) Google doesn’t support the handling of <field> elements with simple errors or typos
This new statement in the documentation is in direct opposition with the production code shared on Github.

According to this code, Google still accepts simple errors and typos such as a missing hyphen between “user” and “agent”, an extraneous “s” in “dissallow” or even a missing colon between the directive and the path (e.g. disallow page.html)
The time and effort spent by Google, and others, on making the robots.txt protocol an Internet standard, and updating the documentation as well as making their production code open source, is truly appreciated.
However, some confusion and inconsistencies still exist and testing remains the only true way to be sure of something.
Additionally, not much has changed. Nothing is “undefined”, the length of the path determines how strong the directive is, and wildcards (*) count. You can use them at your advantage (simply add an explicit * at the end of the path to make it stronger). Directives with paths starting with a * also work, and (some) typos still appear to be supported (only by Google, not Bing nor Baidu).
The only big change is quite ironic: the noindex rule, which was never officially supported, is now officially not supported. If you’re currently relying on it, make sure to implement another way to prevent indexing before September 1, 2019.
Special thanks to Merkle’s Connie Xin for her help and research for this article.
If you have any questions let me know on Twitter: @hermesma.



